前言
本教程会以实例来教大家入门“网络爬虫”,让大家可以自己写出属于自己的爬虫程序。
我是木下瞳,请多指教。
公众号:木下学Python

要是大家有什么问题可以在公众号中找到我噢。
可以添加我微信,备注【爬虫】进专栏交流群,和大家探讨你说遇见的困惑噢。

网络爬虫简介
“网络爬虫”又称“网络蜘蛛”。是一种在互联网上自动采集数据的自动化程序,爬虫的规模可大可小,大到百度,谷歌搜索,小到自动下载图片等。
采集数据,所采集的数据是结构化的,批量提取,提高效率的。例如,一张评论系统的网页,上面有用户名,性别,年龄,图片,广告,评论内容,点赞等,我们只想要其中的用户名,性别,其他的都不要,以表格形式保存,表格就是结构化以后的结果,如果这张网页只有一页那可以手动复制粘贴,那有 1000,100000 张呢,显然复制粘贴效率就太低了还不能保证正确率,使用爬虫提取,正确率都,效率都得意保证,下次再有类似的网页,改一改就可以用。
爬虫的本质是网络请求,请求访问一个网页获得响应后,提取其中的数据。当然爬虫还可以干其他的,抢票,下载图片视频等。
我们在接下来的教程中会以实际例子来讲解爬虫的知识点。
要是觉得此爬虫教程有帮助,可以给小编木下瞳打打赏~
让木下瞳更有动力写出更好的教程给大家学习噢~
路漫漫其修远兮,吾将上下而求索,自学之路不易,与君共勉,加油~

pycharm 下载
我们使用 pycharm 来进行爬虫的编写,所以需要下载个 pycharm,下载地址:
https://www.jetbrains.com/pycharm/
新建项目
首先要新建个空项目文件夹,用来保存我们写的爬虫文件,一定要空的,否则会失败!!!
然后依次点击左上角 File -> New Project
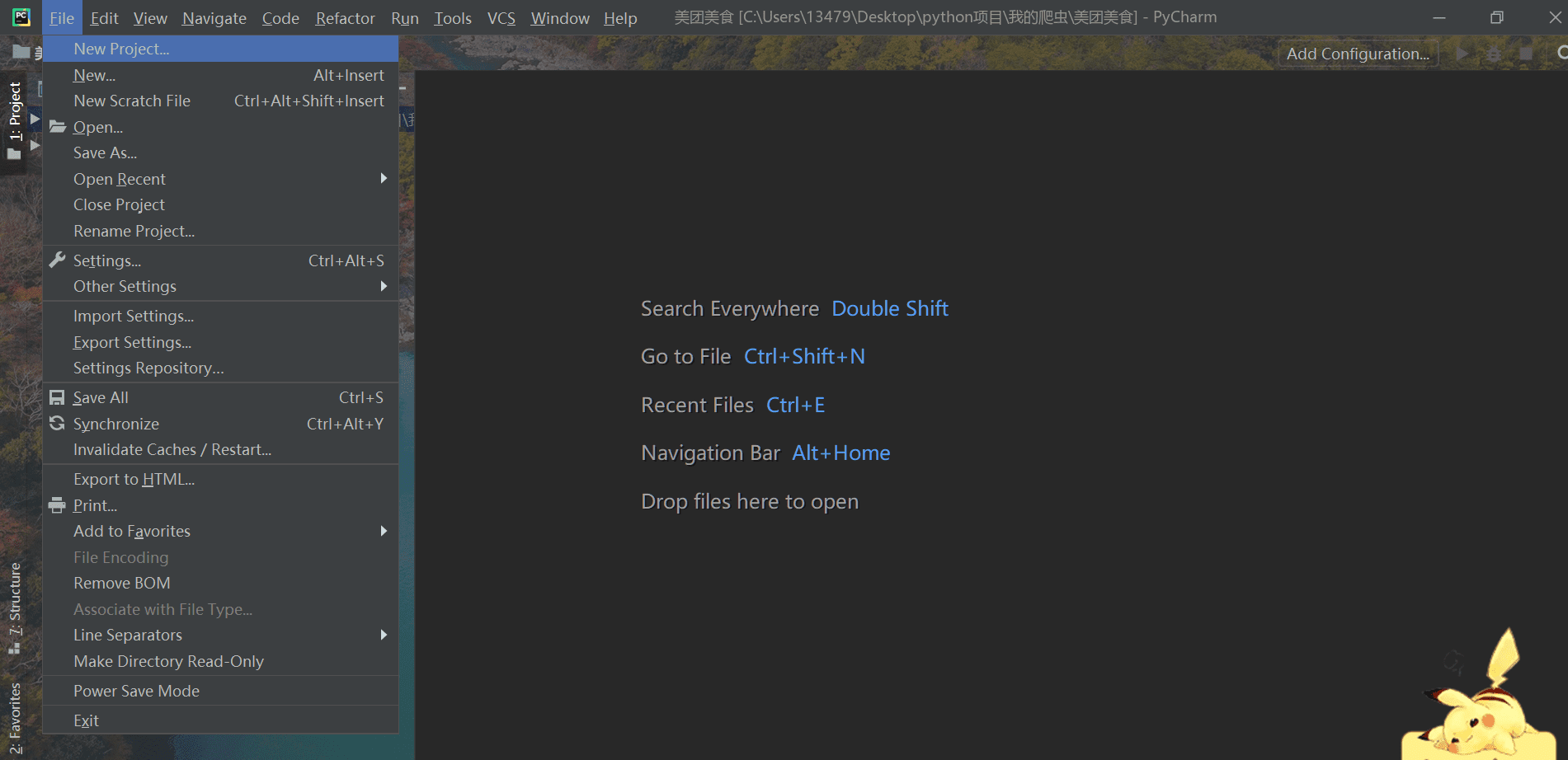
然后会弹出如下
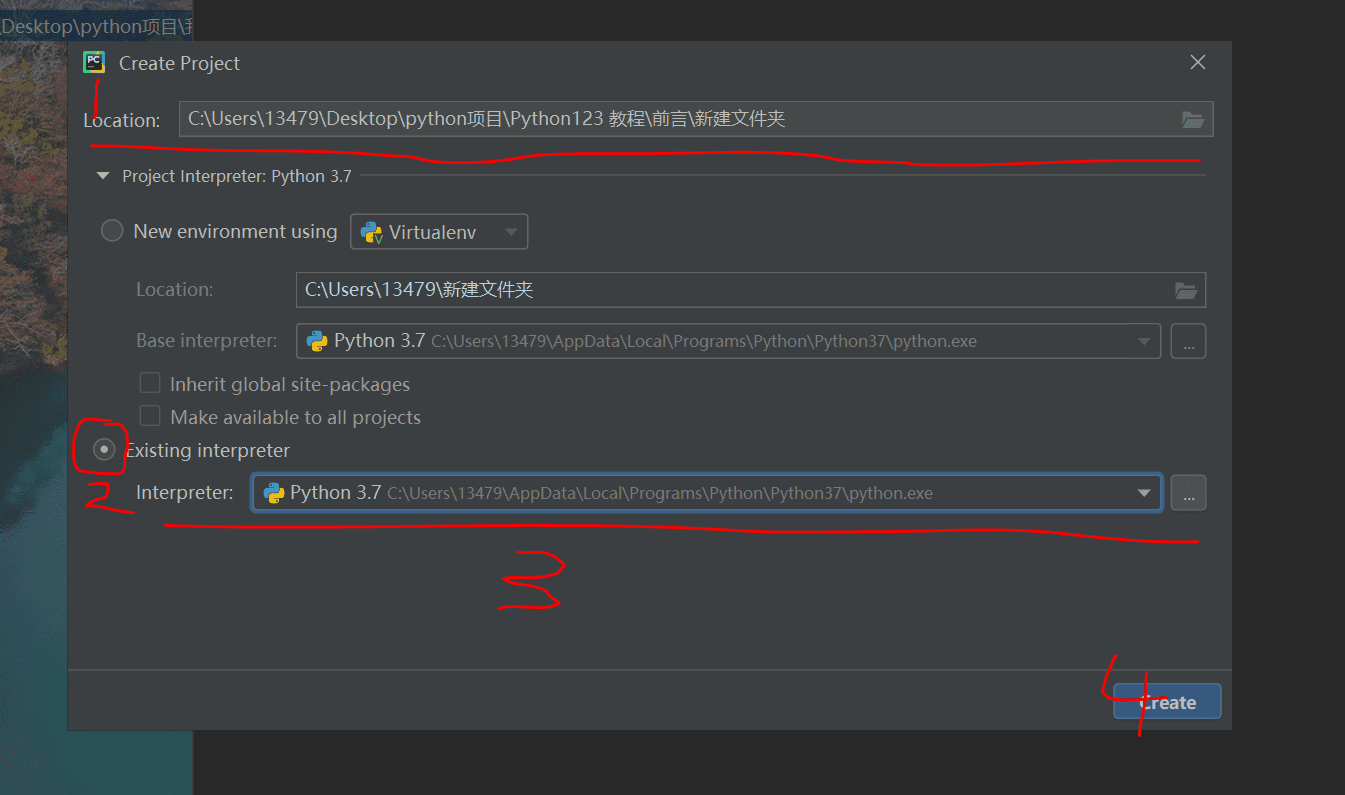
1:把路径设置成刚刚建的空文件夹
2:选择现有环境,指的是你电脑下载的 python 环境
3:你的电脑下载的 python 的环境的路径,可以照着我这样来寻找,其中 13479 是我的用户名,换成你的
4:创建
然后在按照下面的顺序新建 py 文件
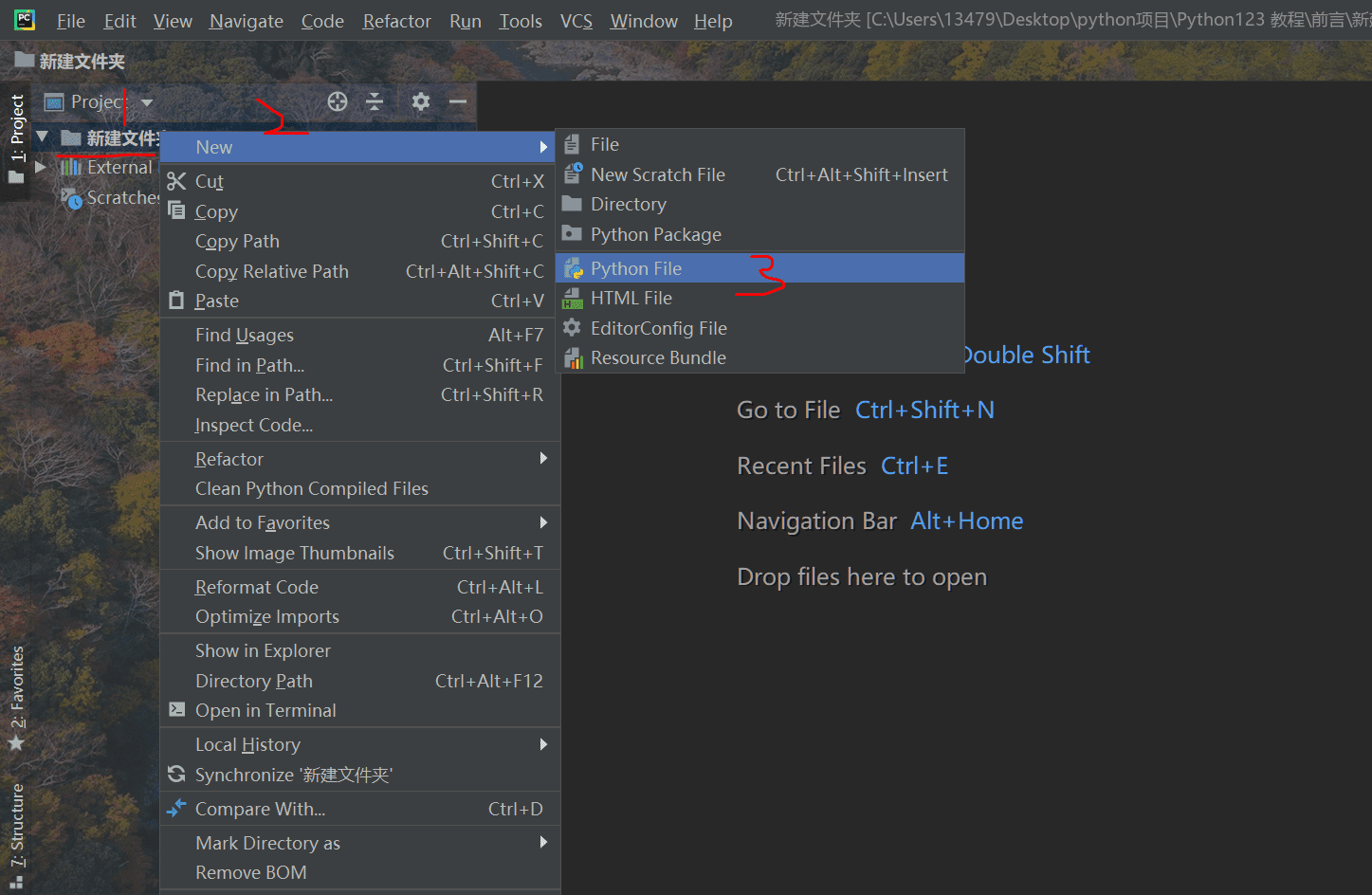
即可以开始编写程序
