Start
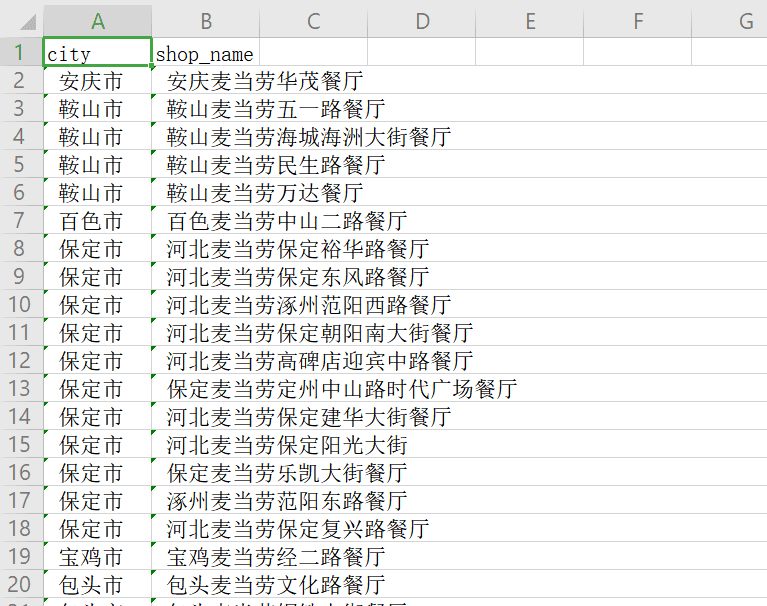
我们此次目标是麦当劳店铺数据集,城市,店铺名,然后写入 csv 保存
csv 是我们常用的种文件格式,以逗号分割,和表格很像
https://www.mcdonalds.com.cn/index/Quality/publicinfo/deliveryinfo?page=
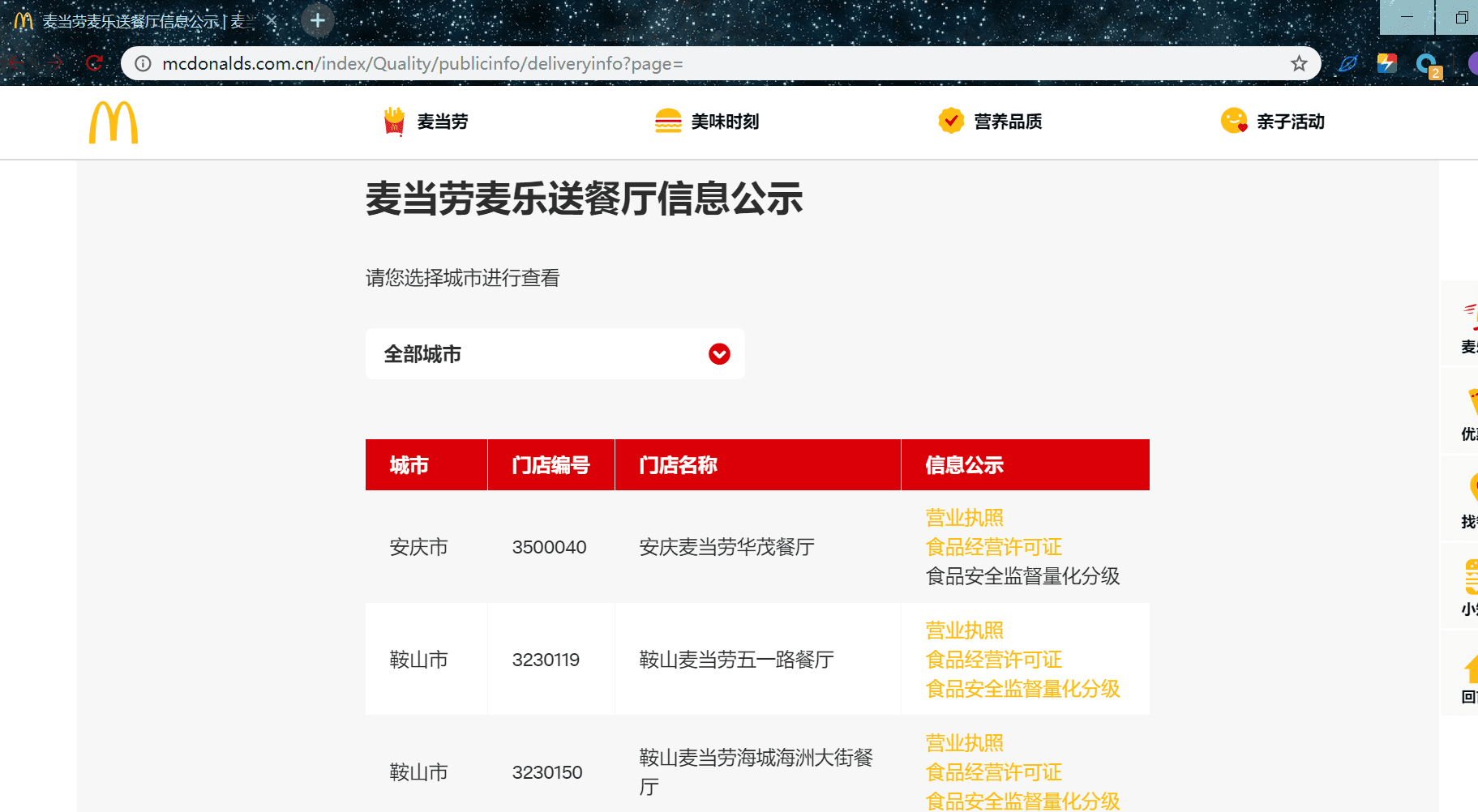
url 构造
我们翻几页,可以看到只有一个 page 字段在变化,所以我们很容易得到我们的所有页数的 url:
mc_url = ['https://www.mcdonalds.com.cn/index/Quality/publicinfo/deliveryinfo?page={}'
.format(str(i)) for i in range(1,236)]
分析
选中一个城市名复制,右键查看网页源代码,能搜索到,说明是静态的
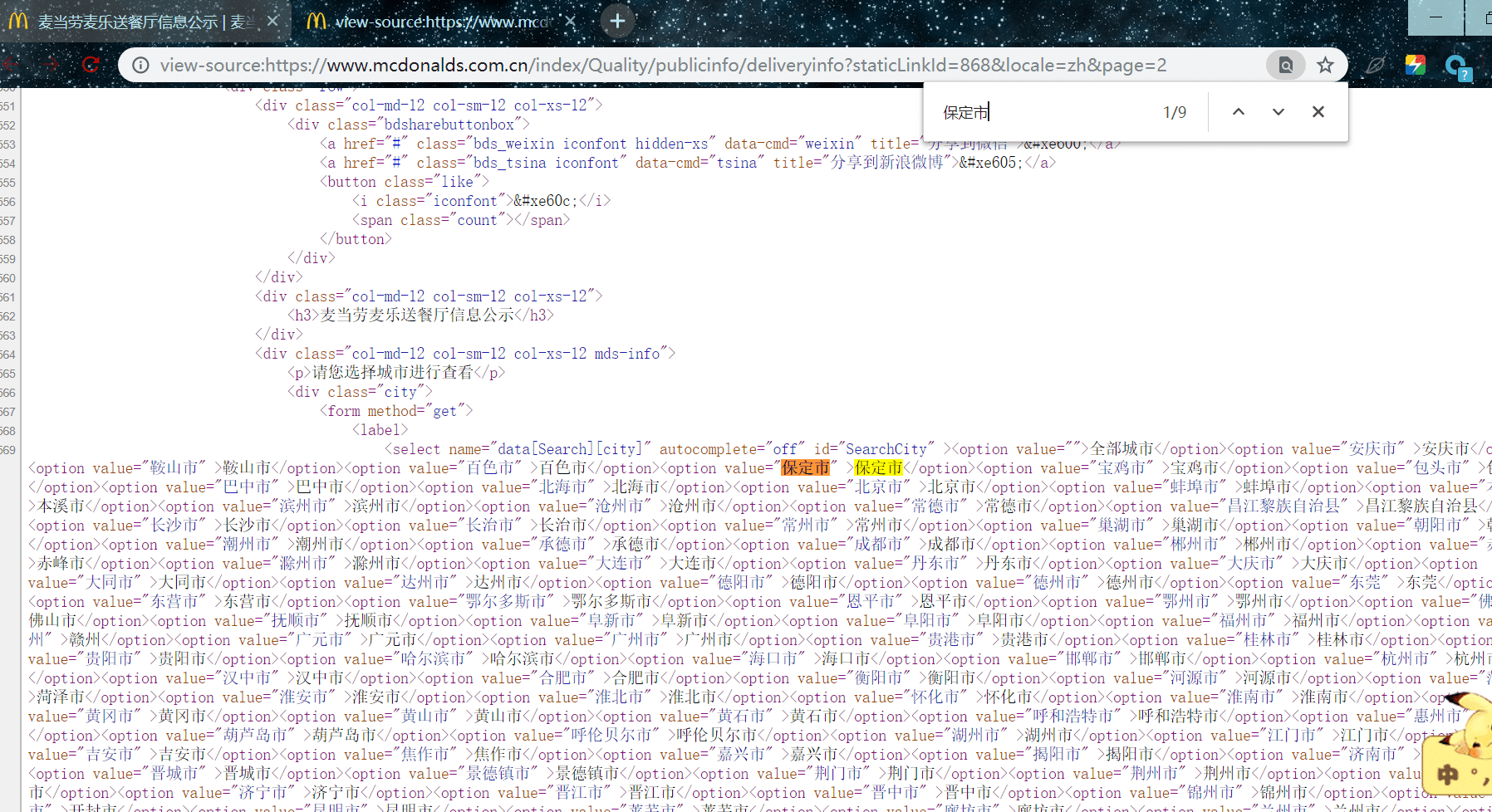
我们可以构造正则表达式提取每一页的城市名,店铺名:
pat1 = '<span>城市</span>(.*?)</td>'
cities = re.findall(pat1,html,re.S)
pat2 = '<span>门店名称</span>(.*?)</td>'
shop_names = re.findall(pat2,html,re.S)
csv 存储
我们需要先创建一个 csv 文件,先写入第一行头信息
def create_csv_header():
'''
创建 csv,并写入第一行头信息
:return:
'''
with open('mc.csv','a+',encoding='utf-8',newline='') as f:
# 创建写入对象
writer = csv.writer(f)
# 写入第一行头信息
writer.writerow(['city','shop_name'])
a+:为追加模式,在文件后继续写入,不清空原来的,没有文件就创建,我们是爬一页写入一页,+ 代表可读,所以用 a+ 我们可边运行边查看
newine='':意思是每一行数据中间不空行,如果没有它,那每一行中间都有一个空行,看着不舒服
在写入 csv ,需要先创建一个写入对象,当然需要导入 csv 库,内置的,写入数据是用 writerow 写入一行,其中是传入列表或元组的形式,每一个索引对应 csv 表格中每一列,第一个是第一列的数据,第二个是对应第二列的数据
上面是写入一行头文件,写入多行的数据也是同理,只不过是循环写入:
def write_csv(data):
'''
写入 csv
:param data:
:return:
'''
with open('mc.csv','a+',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
for _ in data:
writer.writerow(_)
END
这样我们的数据就保存下来了,可以转发给别人的形式,下面给源码,要是跑出来 csv 文件是乱码,encoding = 'utf-8',改成 encoding = 'gbk'
完整代码
import requests
import re
import time
import csv
from fake_useragent import UserAgent
def create_csv_header():
'''
创建 csv,并写入第一行头信息
:return:
'''
with open('mc.csv','a',encoding='utf-8',newline='') as f:
# 创建写入对象
writer = csv.writer(f)
# 写入第一行头信息
writer.writerow(['city','shop_name'])
def get_html(url):
'''
下载 html
:param url:
:return:
'''
ua = UserAgent()
headers = {'User-Agent': ua.random}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return
def info(html):
'''
解析麦当劳响应,获取数据
:param response:
:return:
'''
pat1 = '<span>城市</span>(.*?)</td>'
cities = re.findall(pat1,html,re.S)
pat2 = '<span>门店名称</span>(.*?)</td>'
shop_names = re.findall(pat2,html,re.S)
infos = zip(cities,shop_names)
return infos
def write_csv(data):
'''
写入 csv
:param data:
:return:
'''
with open('mc.csv','a+',encoding='utf-8',newline='') as f:
writer = csv.writer(f)
for _ in data:
writer.writerow(_)
if __name__ == '__main__':
'''
主接口
'''
mc_url = ['https://www.mcdonalds.com.cn/index/Quality/publicinfo/deliveryinfo?page={}'
.format(str(i)) for i in range(1,236)]
create_csv_header() # 创建 csv ,并写入第一行头信息
for url in mc_url:
html = get_html(url)
data = info(html)
write_csv(data) # 写入 csv
time.sleep(1)
结果截图