Start
我们这次来爬取豆瓣 python 图书
https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=0
流程
我们已经介绍了 selenium 是模拟人为去访问,我们需要先导入库,并实例化一个浏览器对象,相当于人为打开浏览器:
from selenium import webdriver # 打开浏览器
# 实例化浏览器对象
broswer = webdriver.Chrome()
然后我们需要打开目标 url,相当于人为输入网址:
url = 'https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=0'
# 打开网页
broswer.get(url)
在人为输入网址后,会弹出相应的网页,只不过在弹出之前,我们一般都会有一点时间的等待,由于网速现在都比较快,所以只是一瞬间,但在 selenium 也需要等待,这里等的是网页加载出来,那怎么判断网页是否加载出来呢?我们可以选定网页中的一个元素作为参照,只要此元素出来了,那网页就代表打开了,所以编写代码等待元素加载,我们选取的是书本标题作为参照,右键检查查看元素标签:
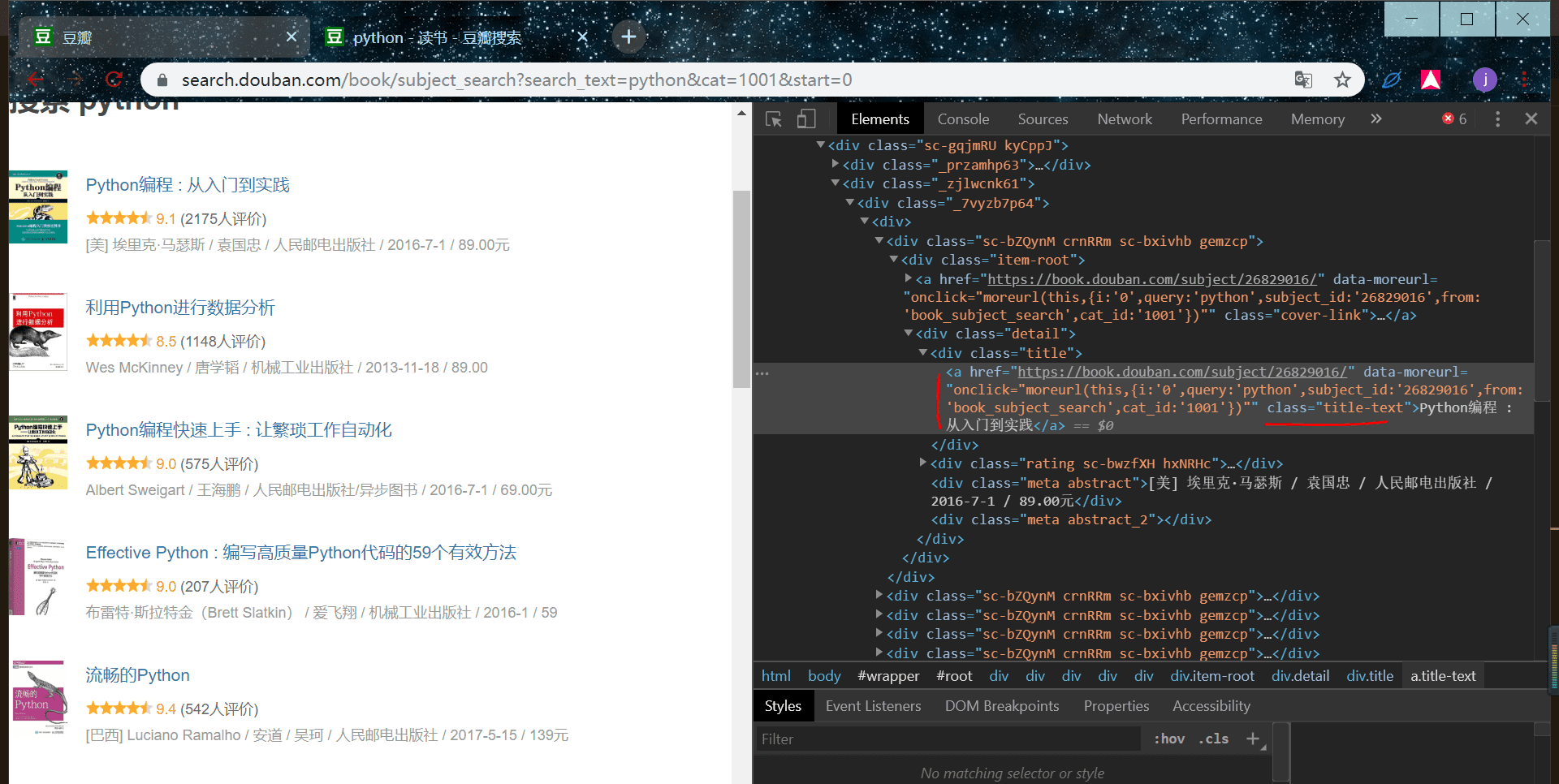
我们看到它对应的属性有一个 class ,那我们可以以它作为判断依据:
在等待的代码中需要另外导入三个库
#实现等待需要用到下面三个库
from selenium.webdriver.common.by import By #用于指定 HTML 文件中 DOM 标签元素
from selenium.webdriver.support.ui import WebDriverWait #等待网页加载完成
from selenium.webdriver.support import expected_conditions as EC #指定等待网页加载结束条件
# 等待元素加载出来
WebDriverWait(broswer, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'title-text')))
这是一种写法,其中 By.CLASS_NAME 可以换其他的方法
broswer:浏览器对象
10:显示等待 10秒,在此时间类,元素没有出现,则抛出异常
EC.presence_of_element_located:判定的方法为选择此页面的元素
By.CLASS_NAME, 'title-text' :通过 class 属性的 title-text 值来判断
然后我们提取书名,评分,出版信息,使用 xpath 表达式提取,在 selenium 中的是 find_elements_by_xpath 方法:
# 提取书名,评分,出版信息的标签
book_names = broswer.find_elements_by_xpath('//a[@class="title-text"]')
scores = broswer.find_elements_by_xpath('//span[@class="rating_nums"]')
publish_infos = broswer.find_elements_by_xpath('//div[@class="meta abstract"]')
我们提取到的是标签的列表,但我们需要的是其中的文本,我们可以用 text 方法提取出然后打印:
# 从标签中提取数据
for book_name,score,publish_info in zip(book_names,scores,publish_infos):
book_name = book_name.text
score = score.text
publish_info = publish_info.text
print((book_name,score,publish_info))
最后提取完这一页,我们需要翻页,就需要捕捉下一页的元素的标签,然后点击,我们可以通过事后捕捉的下一页的标签来判断是否是最后一页了:
# 定位 ‘后页’ 的元素,并点击
next = broswer.find_elements_by_xpath('//a[@class="next"]')
if next == []: # 判断是否是最后一页
break
else:
next[0].click()
END
到这里,我们就提取结束了,但我们只介绍了 selenium 中一些基本操作,在后面遇见复杂的在来说明吧,用它提取淘宝商品数据是一个比较合适的选择
完整代码
# coding=gbk
from selenium import webdriver # 打开浏览器
#实现等待需要用到下面三个库
from selenium.webdriver.common.by import By #用于指定 HTML 文件中 DOM 标签元素
from selenium.webdriver.support.ui import WebDriverWait #等待网页加载完成
from selenium.webdriver.support import expected_conditions as EC #指定等待网页加载结束条件
url = 'https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=0'
# 实例化浏览器对象
broswer = webdriver.Chrome()
# 打开网页
broswer.get(url)
while True: # 循环翻页
# 等待元素加载出来
WebDriverWait(broswer, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'title-text')))
# 提取书名,评分,出版信息的标签
book_names = broswer.find_elements_by_xpath('//a[@class="title-text"]')
scores = broswer.find_elements_by_xpath('//span[@class="rating_nums"]')
publish_infos = broswer.find_elements_by_xpath('//div[@class="meta abstract"]')
# 从标签中提取数据
for book_name,score,publish_info in zip(book_names,scores,publish_infos):
book_name = book_name.text
score = score.text
publish_info = publish_info.text
print((book_name,score,publish_info))
# 定位 ‘后页’ 的元素,并点击
next = broswer.find_elements_by_xpath('//a[@class="next"]')
if next == []: # 判断是否是最后一页
break
else:
next[0].click()# 定位 ‘后页’ 的元素,并点击
结果截图

