目标
https://book.douban.com/top250?start=0
此次的目标是豆瓣图书TOP250,我们爬取TOP250的‘书名’‘出版信息’‘评分’‘评价人数’这四个数据
url 构造
我们查看几页观察观察 url 的变化
第一页:
第二页:
第三页:

最后一页:
我们可看到 url 结构为 https://book.douban.com/top250?start=225 这样的
每翻一页,唯一变化的是 start 参数,由此判断此参数是翻页的相关参数,再看第一页为 0,第二页为 25,第三页为 50,最后一页为 225,每翻一页增加 25,由此使用列表解析得到每一页的 url:
urls = ['https://book.douban.com/top250?start={}'
.format(str(i)) for i in range(0,226,25)]
主接口
在得到 url 后,开始写爬虫逻辑,一次循环每一个 url,先请求,再从中提取数据
def main():
'''
主接口
'''
urls = ['https://book.douban.com/top250?start={}'
.format(str(i)) for i in range(0,226,25)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1)
请求 url
def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return
分析数据
鼠标放在目标元素位置,右键-检查,我们看到第一本书的我们需要的详细信息都在 <tr class="item"> 里面,所以我们需要提取这一页的所有的标签:
# 提取这一页的满足条件的标签
infos = html.xpath('//tr[@class="item"]')
返回的是一个列表,再一次循环列表的每一个标签,从中提取出对应的数据,其实不用提取数据的 xpath 路径不需要去看路径张啥样在去手敲进去,可以复制得,但需要修改
我们以提取书名为例,在书名那里右键-检查,如下图,复制出 xpath 路径
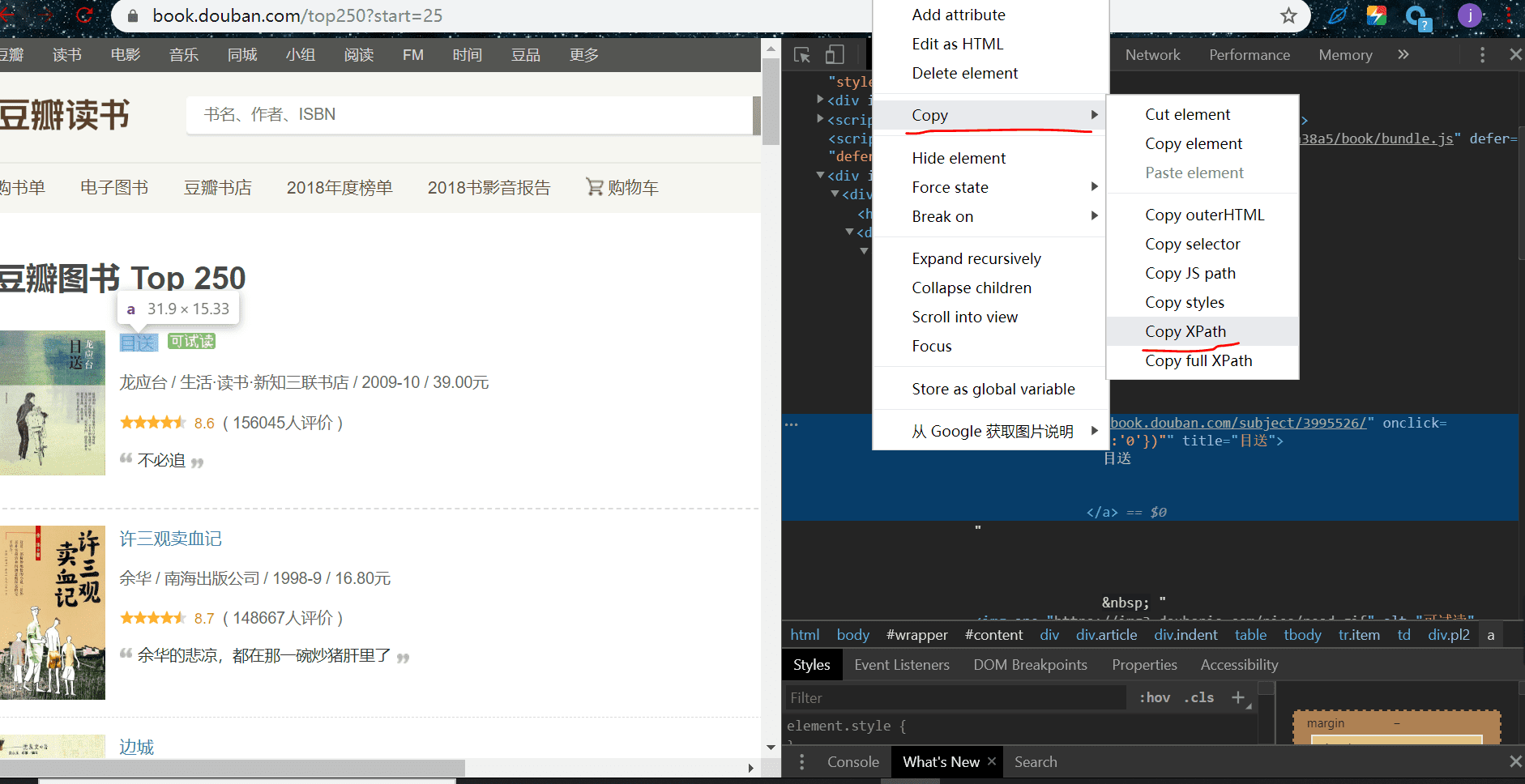
然后粘贴到代码里是这样的
# 书名
name = info.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a')[0]
我们观察我们已经提取的 tr 标签 '//tr[@class="item"]' ,在看上面找到 tr ,以它为断点(包含它),前面的删掉改成如下:
# 书名
name = info.xpath('./td[2]/div[1]/a/text()')[0]
因为我们已经提取了一大包含我们需要的数据的大标签 tr,是从中再提取数据,所以前面多余的删掉,包含 tr 也删掉,因为是从它的里面提取
另外三个数据也是同理
提取数据
def get_infos(html):
'''
提取数据
'''
# 解析 html
html = etree.HTML(html)
# 提取这一页的满足条件的标签
infos = html.xpath('//tr[@class="item"]')
# 循环每一个子标签,提取数据
for info in infos:
# 书名
name = info.xpath('./td[2]/div[1]/a/text()')[0]
# 作者,出版社,出版时间,价格
publish_info = info.xpath('./td[2]/p[1]/text()')[0]
# 评分
score = info.xpath('./td[2]/div[2]/span[2]/text()')[0]
# 评价人数
comment_count = info.xpath('./td[2]/div[2]/span[3]/text()')[0]
data = {
'书名' : name.replace('\n','').replace(' ',''),
'出版信息' : publish_info,
'评分' : score,
'评价人数' : comment_count.replace('\n','').replace(' ',''),
}
print(data)
提取后,我们需要用 replace 把多余字符去掉,最后打印
END
到这里接就完成了提取数据,大家可以多理解对比一下 xpath 路径修改那里,之后给大家完整代码吧
完整代码
import requests
import time
from lxml import etree
def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return
def get_infos(html):
'''
提取数据
'''
# 解析 html
html = etree.HTML(html)
# 提取这一页的满足条件的标签
infos = html.xpath('//tr[@class="item"]')
# 循环每一个子标签,提取数据
for info in infos:
# 书名
name = info.xpath('./td[2]/div[1]/a/text()')[0]
# 作者,出版社,出版时间,价格
publish_info = info.xpath('./td[2]/p[1]/text()')[0]
# 评分
score = info.xpath('./td[2]/div[2]/span[2]/text()')[0]
# 评价人数
comment_count = info.xpath('./td[2]/div[2]/span[3]/text()')[0]
data = {
'书名' : name.replace('\n','').replace(' ',''),
'出版信息' : publish_info,
'评分' : score,
'评价人数' : comment_count.replace(' ','').replace('\n',''),
}
print(data)
def main():
'''
主接口
'''
urls = ['https://book.douban.com/top250?start={}'
.format(str(i)) for i in range(0,226,25)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1)
if __name__ == '__main__':
main()
{'书名': '东方快车谋杀案', '出版信息': '[英] 阿加莎·克里斯蒂 / 陈尧光 / 人民文学出版社 / 2006-5 / 18.00元', '评分': '9.0', '评价人数': '(79495人评价)'}
{'书名': '福尔摩斯探案全集(上中下)', '出版信息': '[英] 阿·柯南道尔 / 丁钟华 等 / 群众出版社 / 1981-8 / 53.00元/68.00元', '评分': '9.2', '评价人数': '(77101人评价)'}
{'书名': '灿烂千阳', '出版信息': '[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2007-9 / 28.00元', '评分': '8.8', '评价人数': '(81199人评价)'}
{'书名': '笑傲江湖(全四册)', '出版信息': '金庸 / 生活·读书·新知三联书店 / 1994-5 / 76.80元', '评分': '9.0', '评价人数': '(77331人评价)'}
......