start
上一节我们讲了,今日头条的抓包怎么找,这一节我们来爬取豆瓣电影短评的评论信息,一般评论类的数据都是 ajax 加载的
https://movie.douban.com/
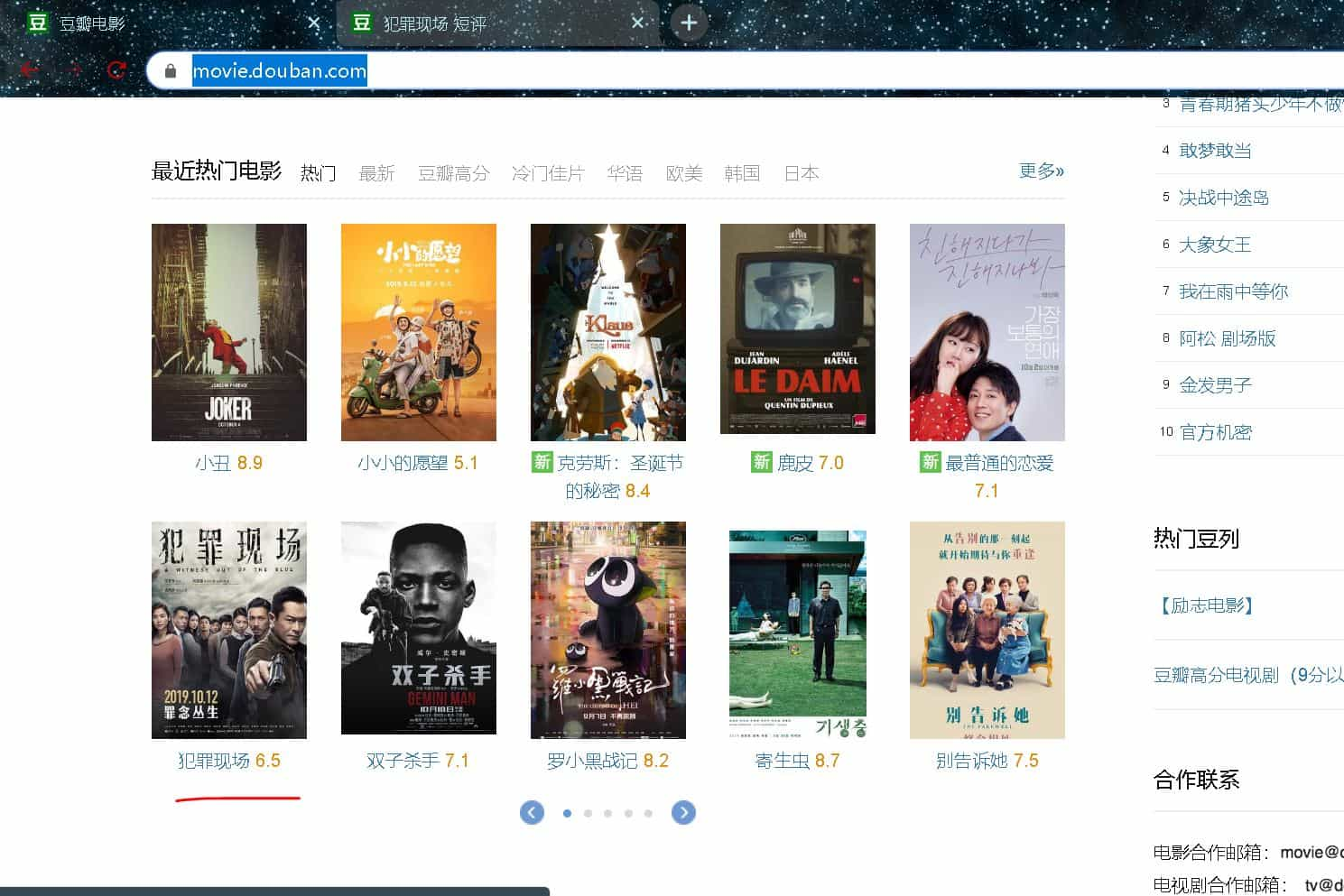
小编选择了 “犯罪现场” 这部电影,来爬取它的短评,点开电影,划到下面找到【更多短评】点进去
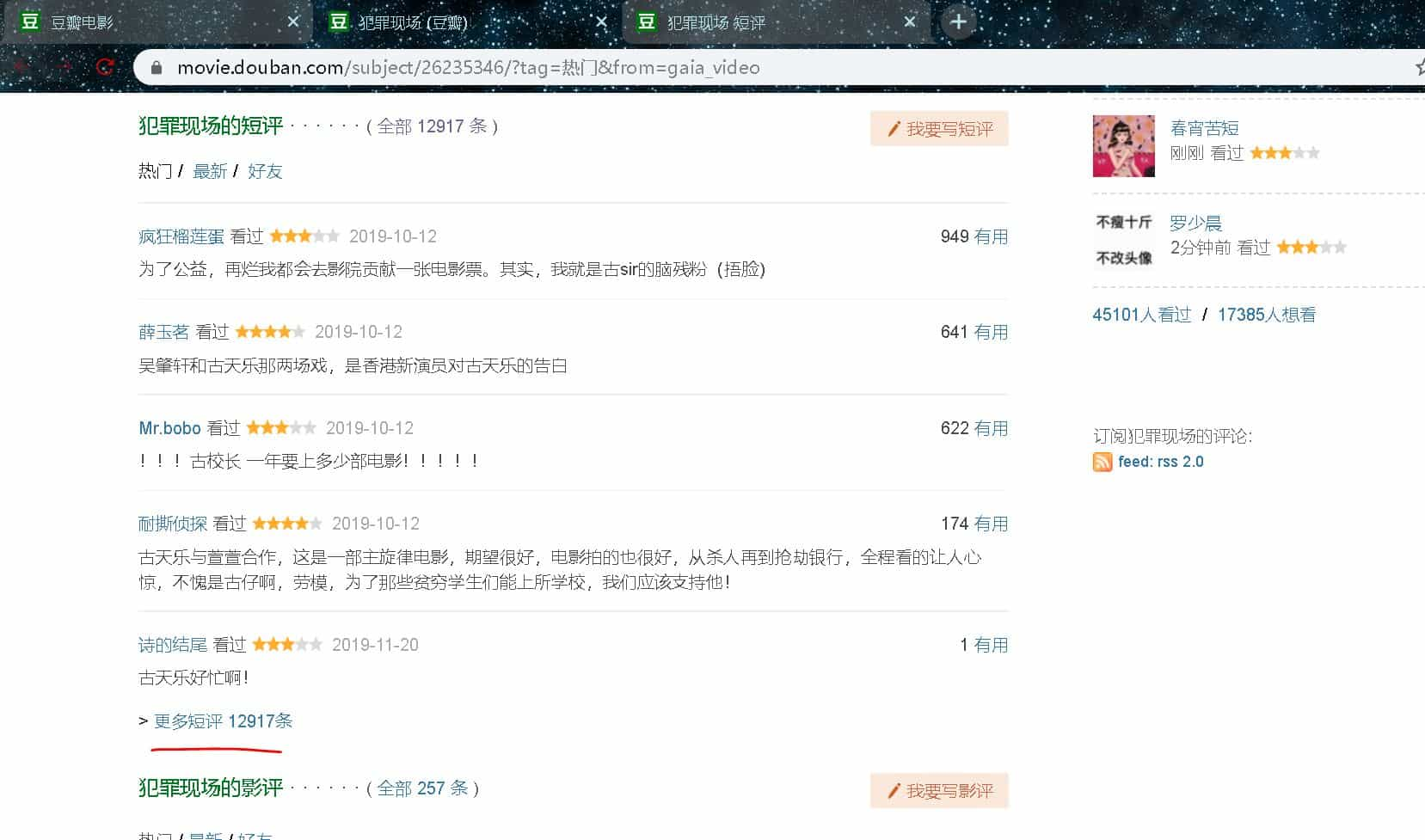
ajax 抓包分析
按 f12,再按 f5 刷新,我们且换到下图所示

我们向后翻两页,看到新加载了两个包
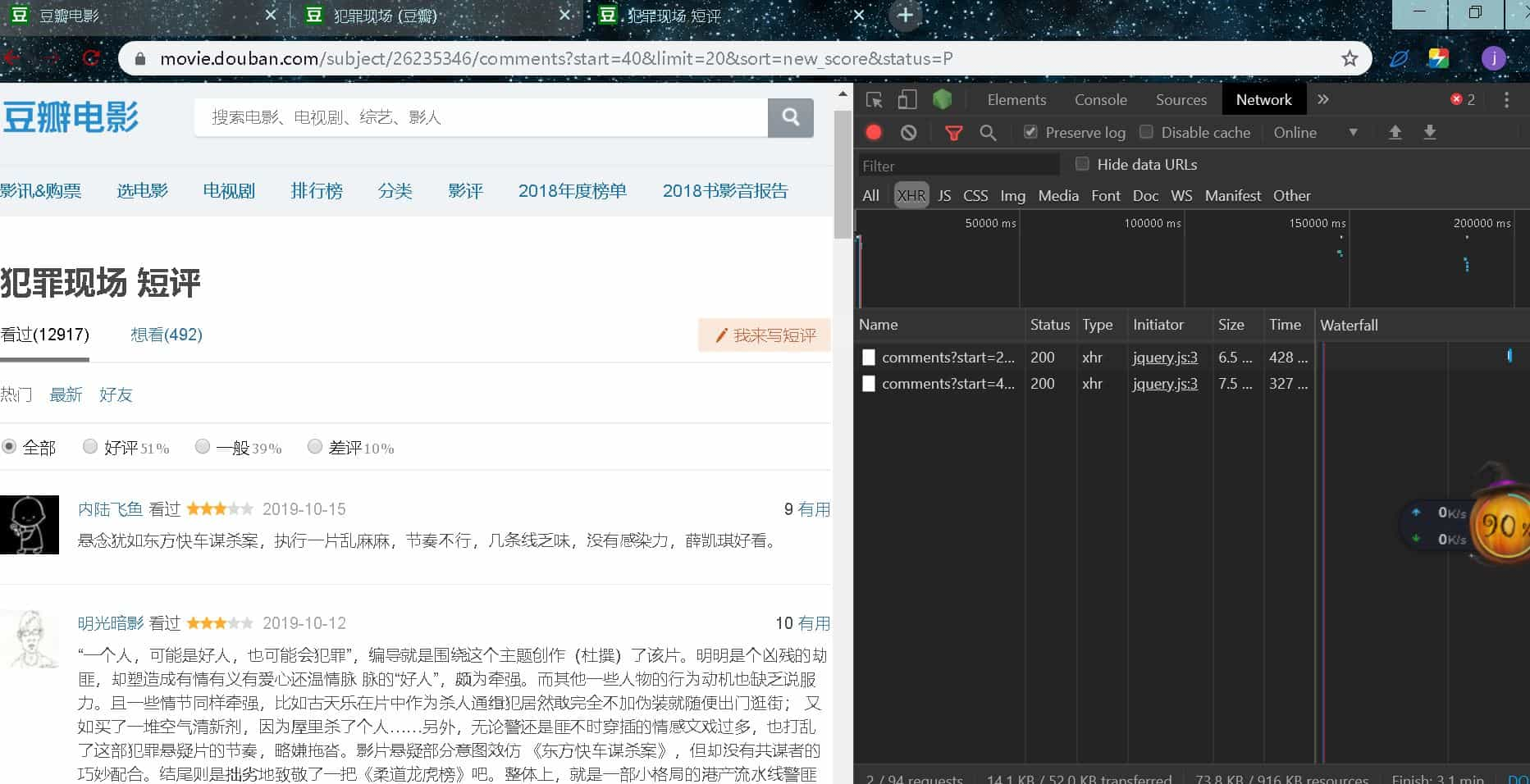
可切换到 Preview 查看这两个包是否为评论数据的包
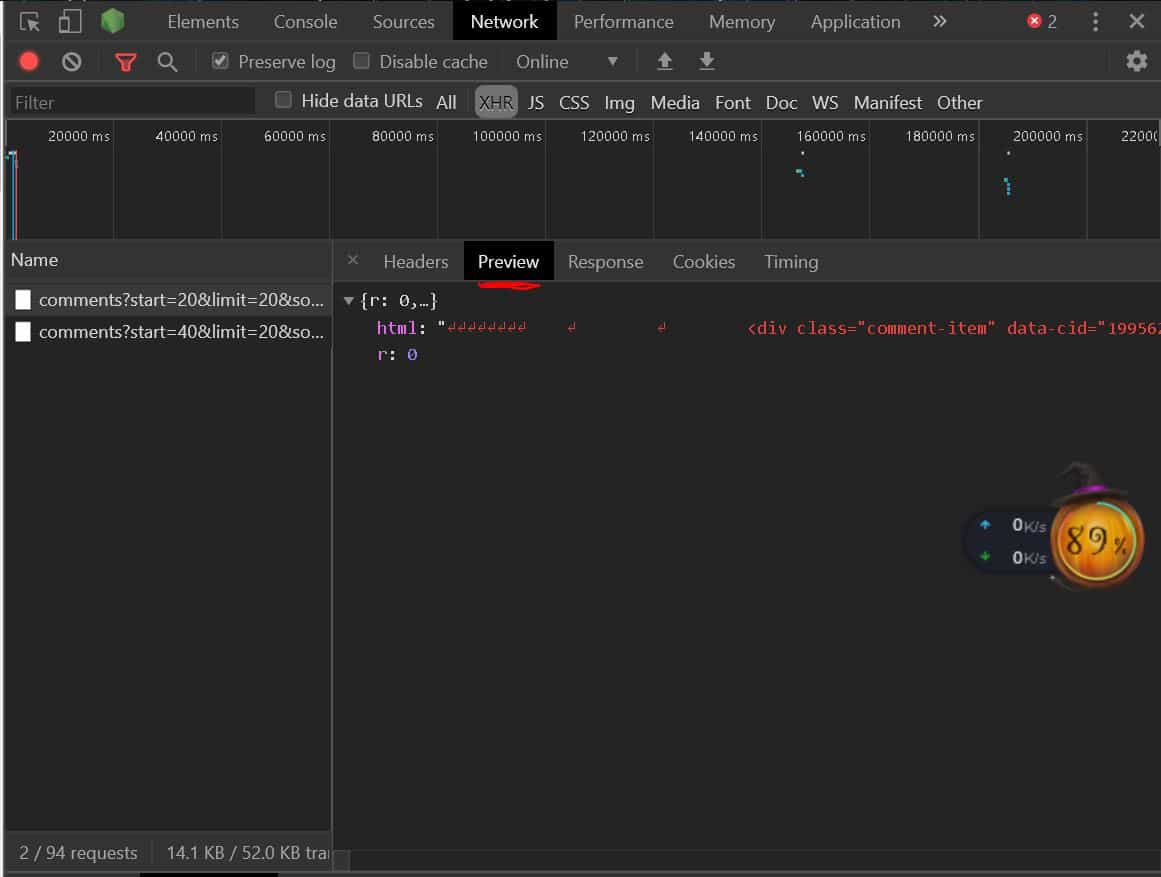
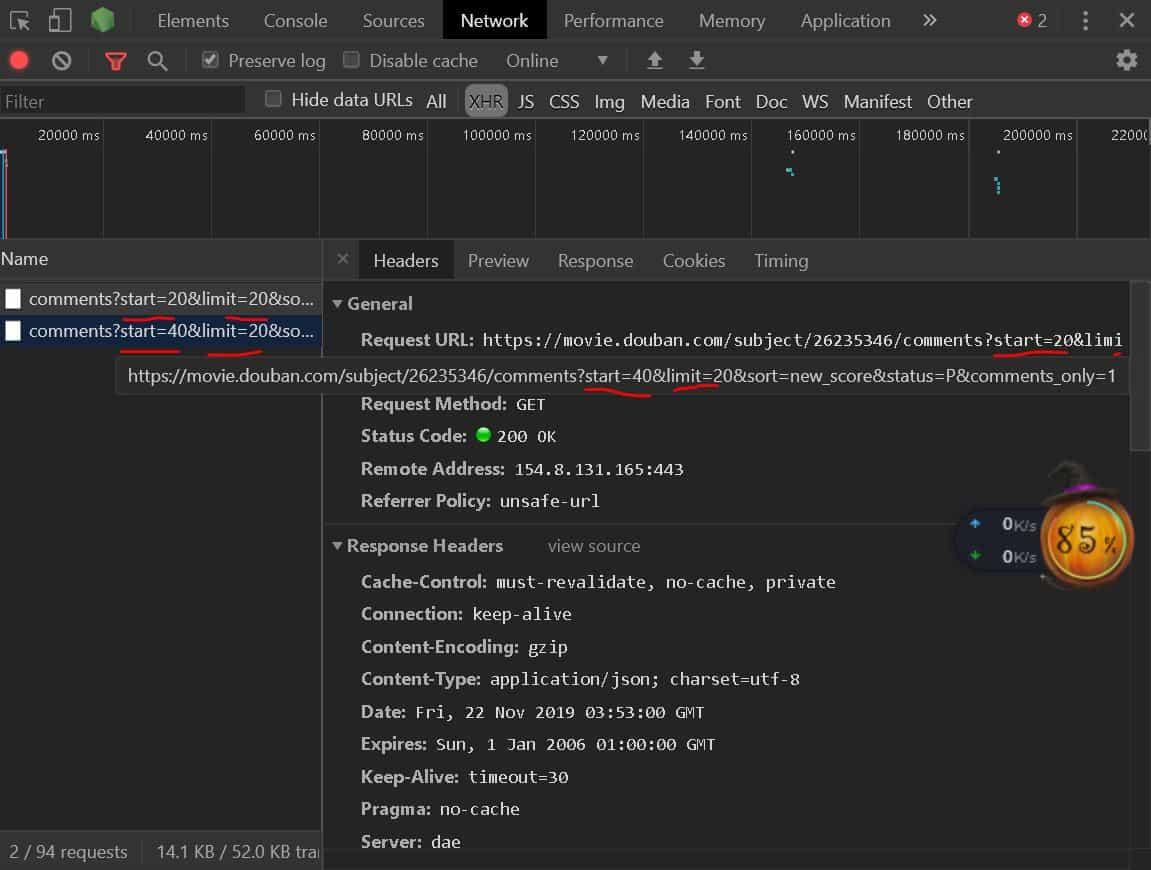
我们对比两个包的 url 可以发现唯一不同的字段为 start,从此可以构造评论数据的 url,其中 limit 的意思是这样的包的请求最多返回多少数据,这里是 20 条,我们可以根据总评论数来计算构造你想爬多少,当然全部爬也可以,小编设置的是 12000 条数据爬取
urls = ['https://movie.douban.com/subject/26235346/comments?start={}&limit=20&sort=new_score&status=P&comments_only=1'
.format(str(i)) for i in range(0,6001,20)]
我们随便选择一条 url 在另外的窗口打开,可以看到,显示的并不是中文,就是说我们去请求返回的数据不会是中文的,下面会教大家这种码怎么转中文

请求获得 html
def get_html(url):
'''
请求网页
:param url:
:return:
'''
count = 0 # 计数请求了几次
while True:
headers = {
'User-Agent' : UserAgent().random,
'Cookie' : '你的 cookie'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response
else:
count += 1
if count == 2:
return
continue
这里我们需要注意了,爬取豆瓣这评论是需要登录的否则会禁止我们访问,我们这里使用 cookie,后面章节会有说。
我们设置了循环请求,目的是一个 url 在请求失败后,可以再次尝试,多次都失败,则跳过。
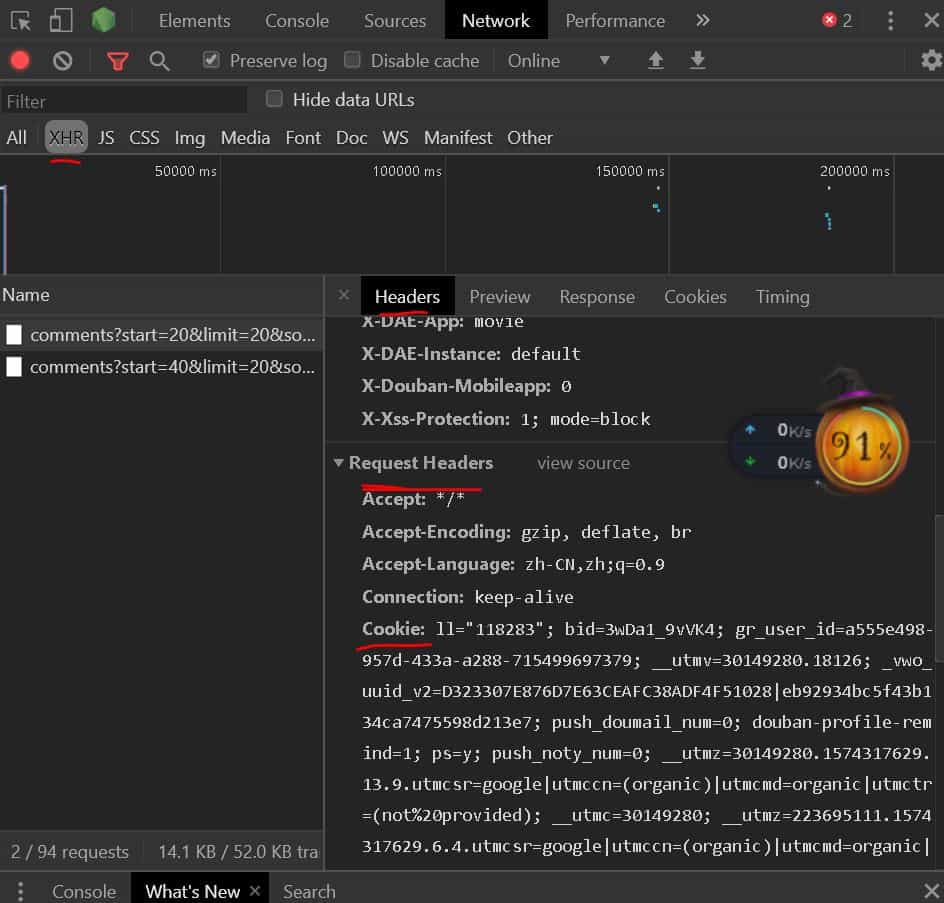
先登录豆瓣,再去查找我们刚刚抓的包,找到 cookie 直接带入代码中的请求头
评论抓取
我们采用正则提取
def get_comments(response):
'''
提取评论
:param response:
:return:
'''
comments = re.findall(r'<span class=\\"short\\">(.*?)</span>',response.text,re.S)
for comment in comments:
try:
print(eval(u"'" + comment + "'"))
print('\n')
except:
pass
pass
正则构造
选择评论右键【检查】,会看到评论数据如下图,由此我们构造第一个正则表达式
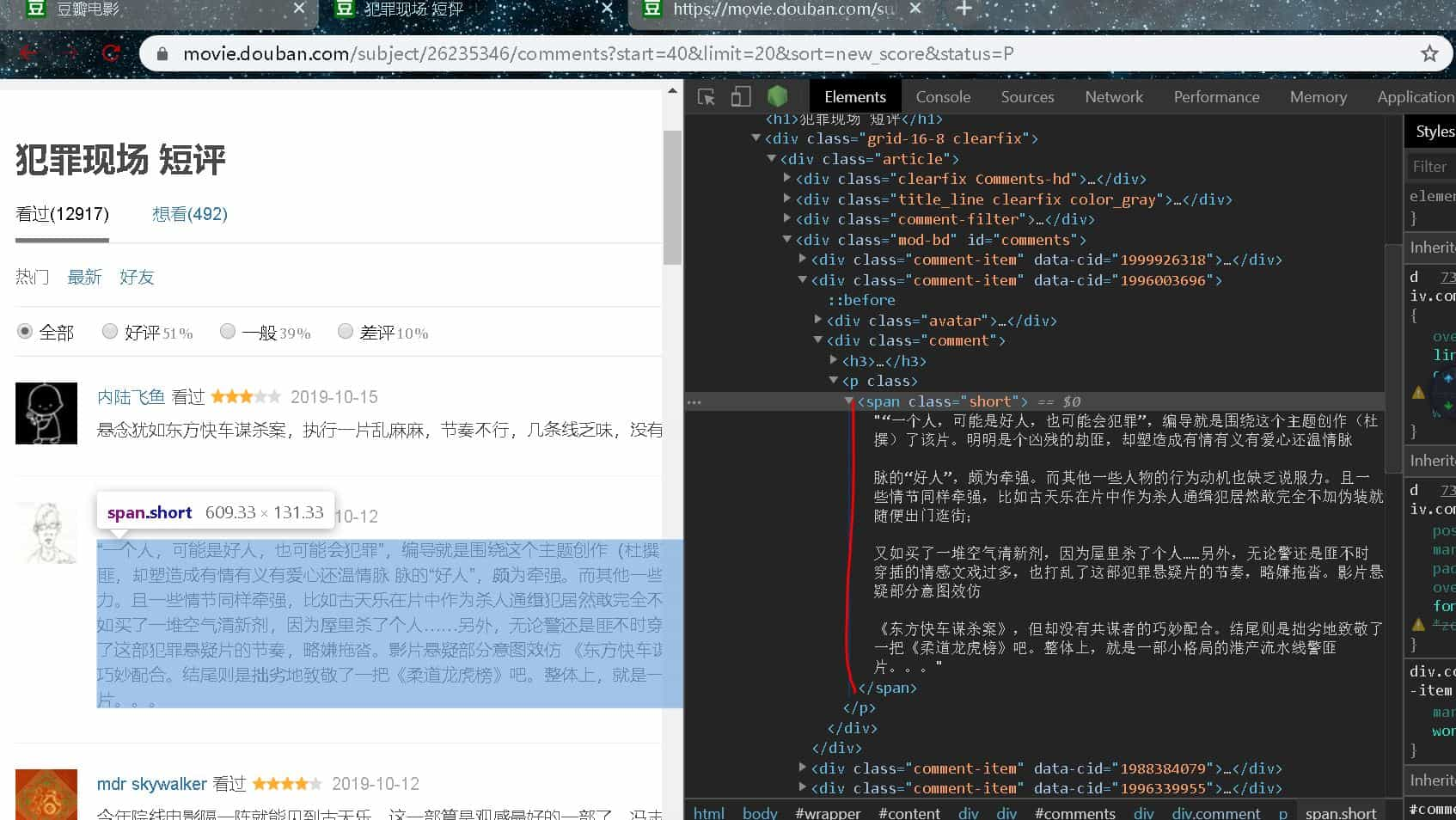
comments = re.findall(r'<span class="short">(.*?)</span>',response.text,re.S)
但使用这个正则表达去提取数据,小编发现,返回是有数据的,但提取不出来,经过小编调试,发现了,我们右键【检查】所看到的代码,与返回的代码不一样
我们选取 一条 url,打开,搜索
<span class="short">
发现没有结果,经过查看对比,发现了真实的是
<span class\"short\">

与之前的多了 “\” 所以我们正则需要加上去,但需要转义,所以真正的正则如下
comments = re.findall(r'<span class=\\"short\\">(.*?)</span>',response.text,re.S)
编码转换
前面提到了我们得到的不是中文,返回的是 Unicode 编码,所以我们使用 eval() 函数来转换,意思是去掉字符串两边引号
我们在编码前后面加上引号,再设置为 utf-8 编码格式,就是前面加个 u,最后再去掉引号,就完成了
print(eval(u"'" + comment + "'"))
最后使用了捕获异常,目的是过滤一些不能转换的评论
END
最后我们来看看是否与评论对应上了
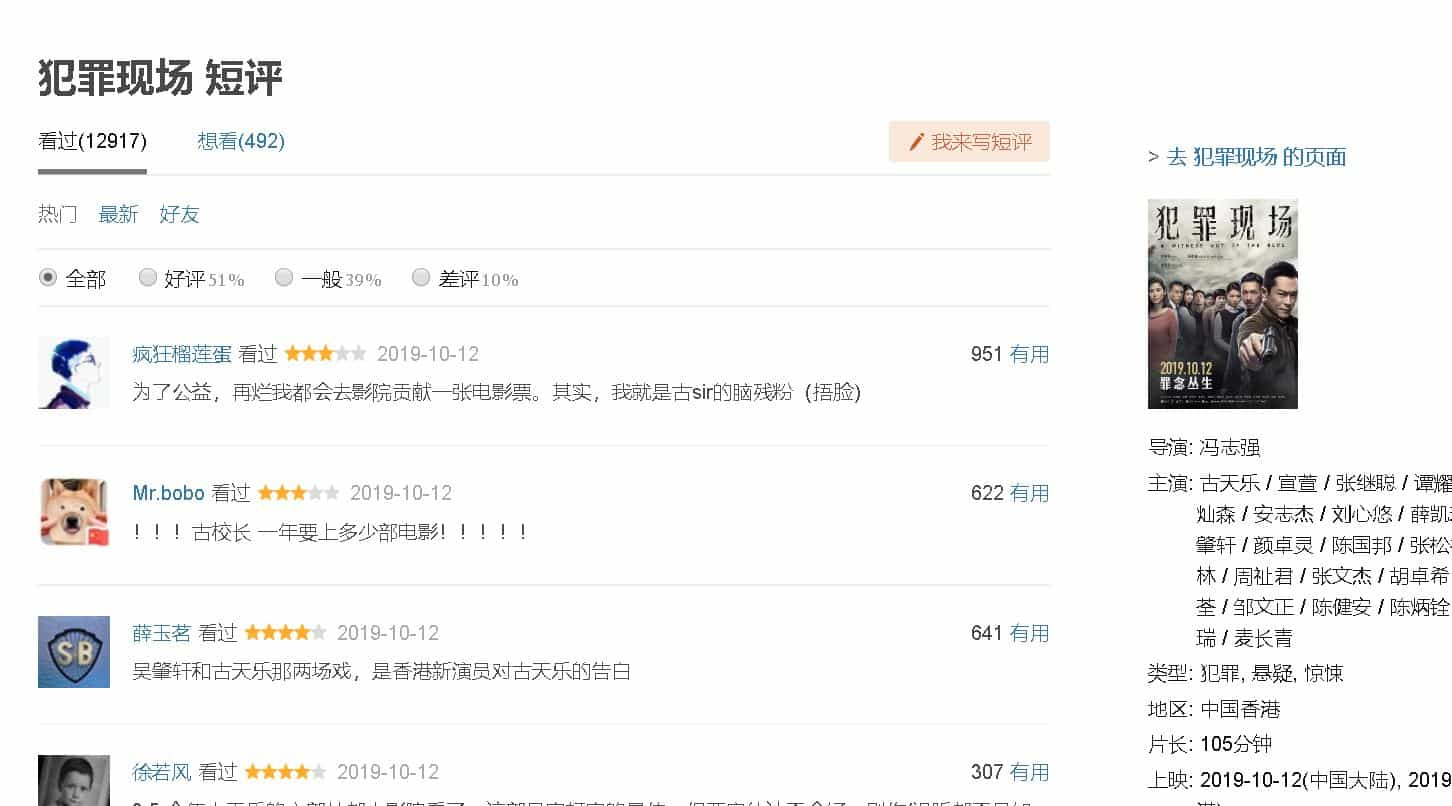
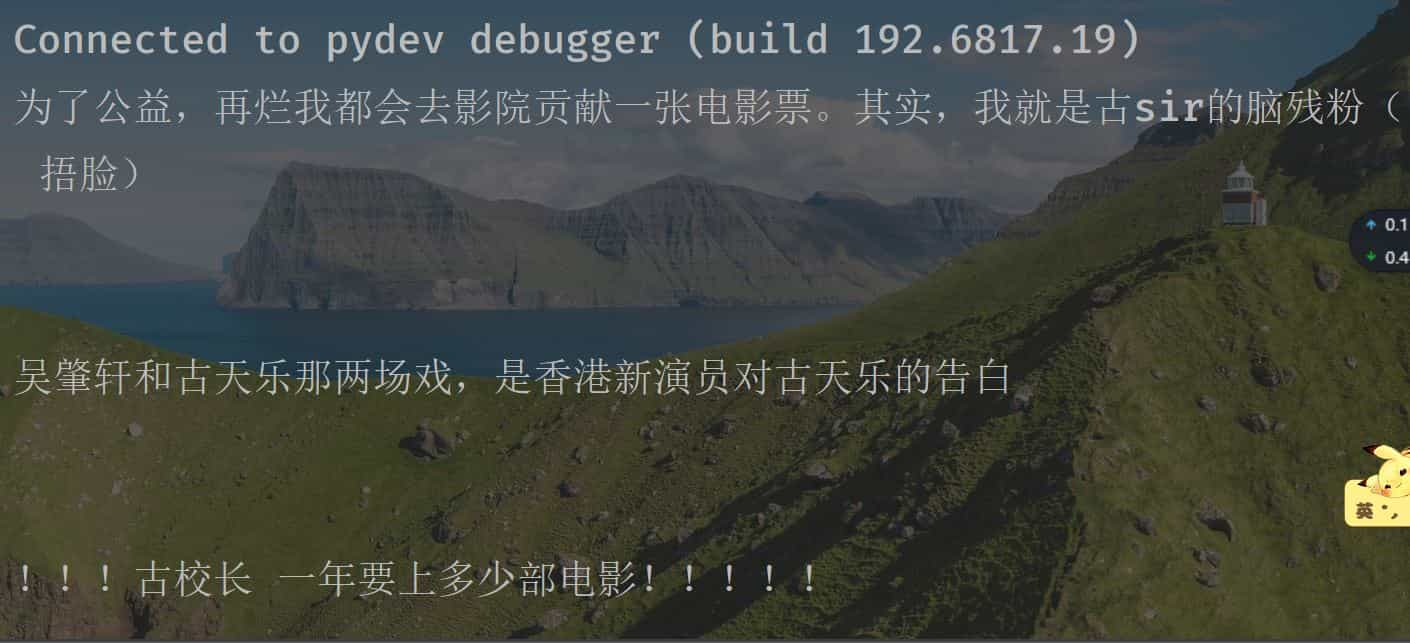
可以看出,我们此次提取完成
完整代码
记住要登录,请求头带上你的 cookie
import requests
import re
from lxml import etree
from fake_useragent import UserAgent
def get_html(url):
'''
请求网页
:param url:
:return:
'''
count = 0 # 计数请求了几次
while True:
headers = {
'User-Agent' : UserAgent().random,
'Cookie' : '你的'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response
else:
count += 1
if count == 2:
return
continue
def get_comments(response):
'''
提取评论
:param response:
:return:
'''
comments = re.findall(r'<span class=\\"short\\">(.*?)</span>',response.text,re.S)
for comment in comments:
try:
print(eval(u"'" + comment + "'"))
print('\n')
except:
pass
pass
if __name__ == '__main__':
urls = ['https://movie.douban.com/subject/26235346/comments?start={}&limit=20&sort=new_score&status=P&comments_only=1'
.format(str(i)) for i in range(0,6001,20)]
for url in urls:
response = get_html(url)
get_comments(response)
pass
