项目分析
本项目主要介绍如何爬取 pdf 电子书文件,具体说明如下:
1)网址为书香清华(http://sxqh.chineseall.cn/home/index)
2)登录爬取
3)python 执行 JavaScript 代码
4)合并 pdf 文件
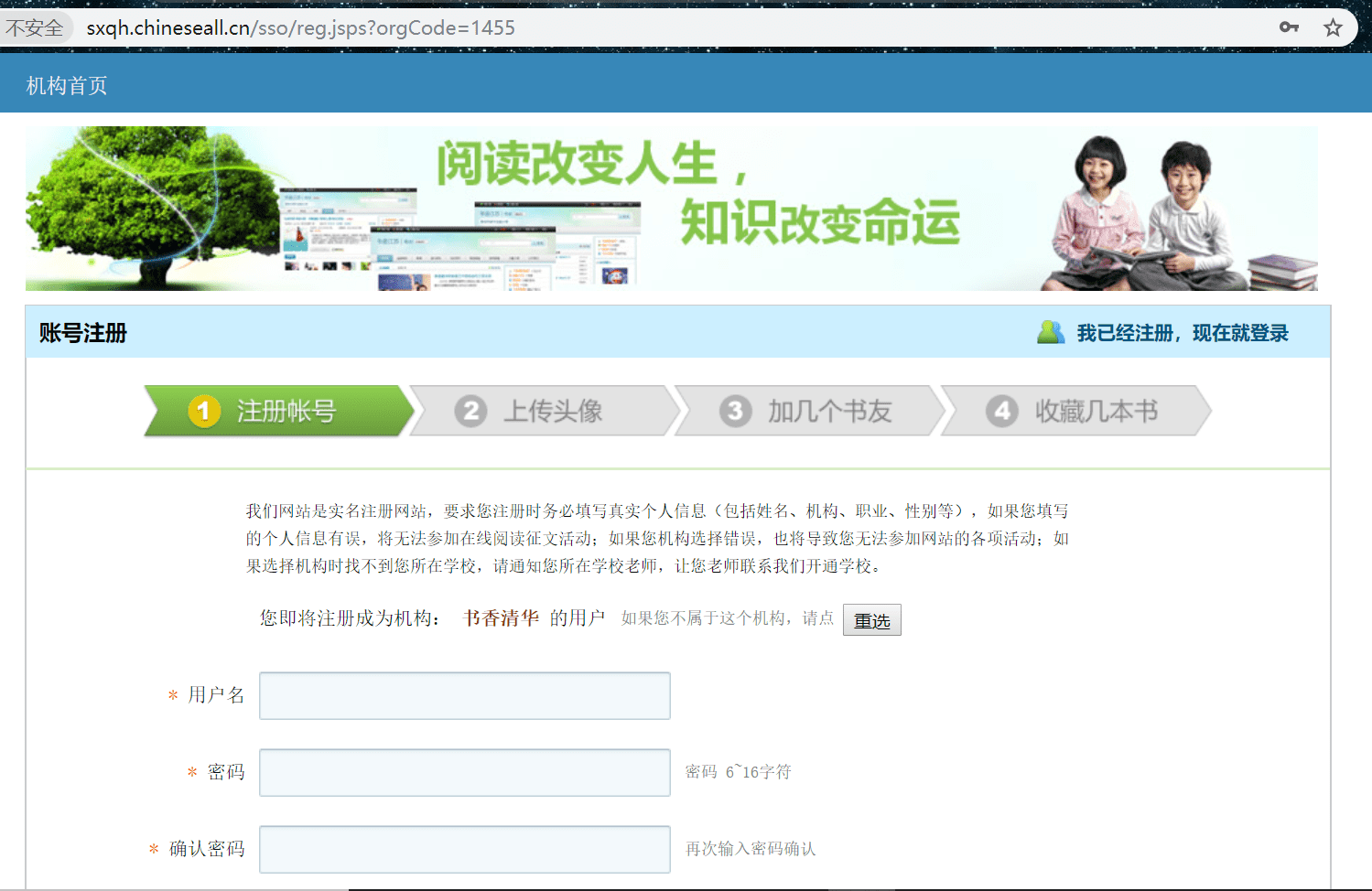
注册账号
打开网页:

注册一个账号:
请求分析
我们以 “精通Scrapy网络爬虫” 此书为例爬取,搜索此书,点开阅读页面:
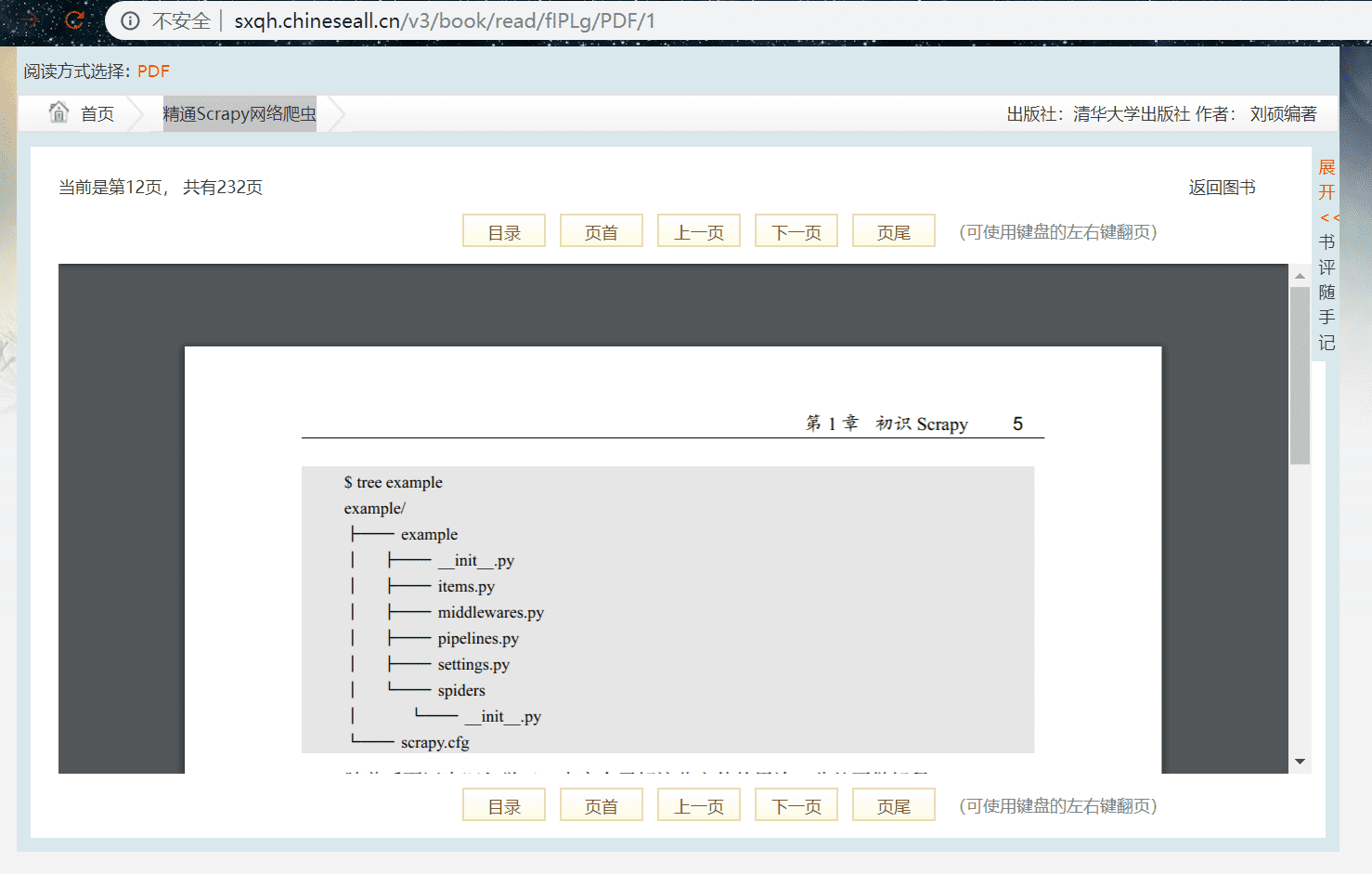
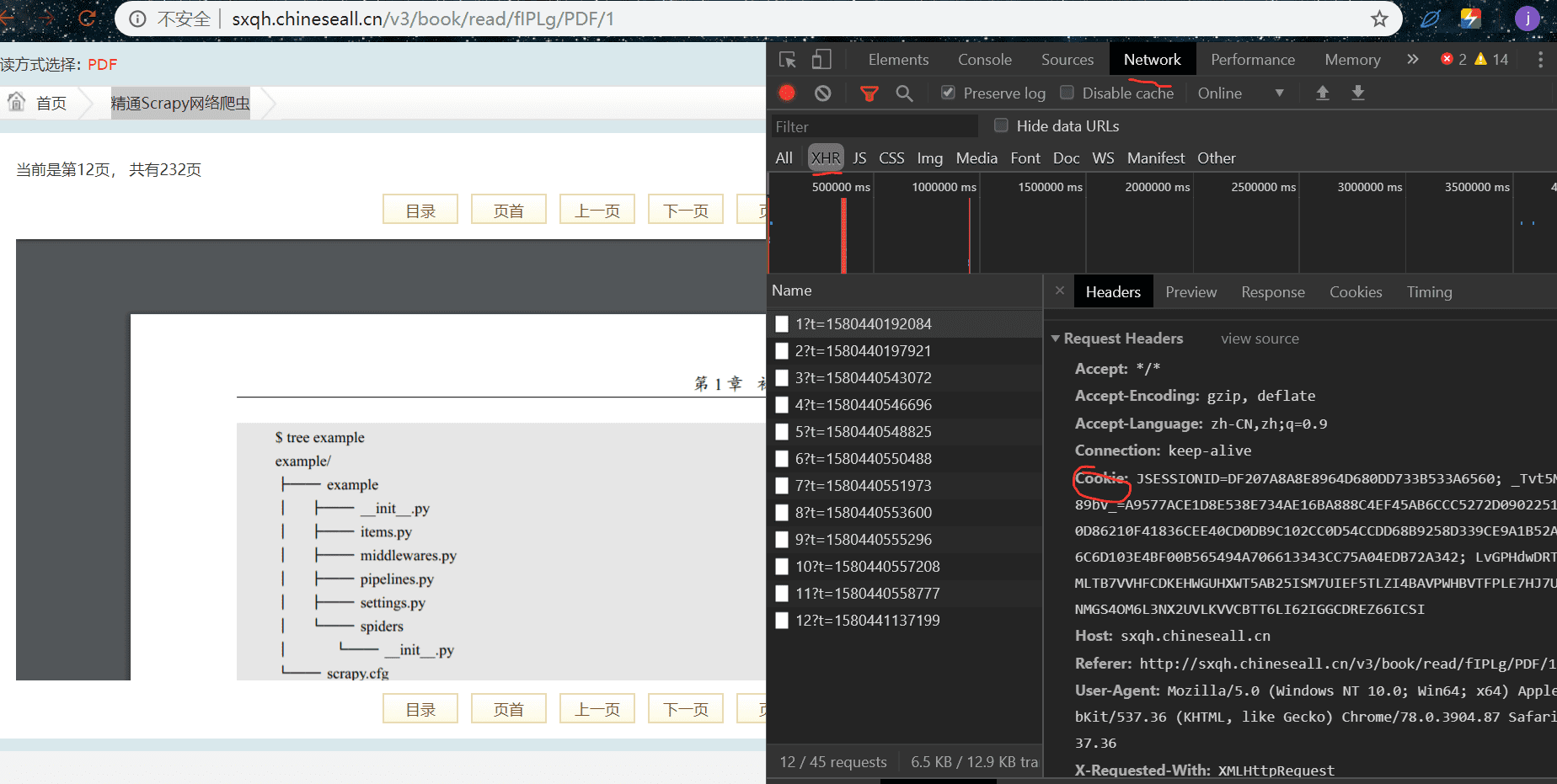
我们翻了几页,翻到第十页的时候,就没有权限查看了,因位需要登录,我们登录即可,我们在翻页过程中 url 没有发生变化,由此得出是 ajax 加载,我们找到对应的包,其中的 cookie 是我们登录后的 cookie,在请求头中需要使用:
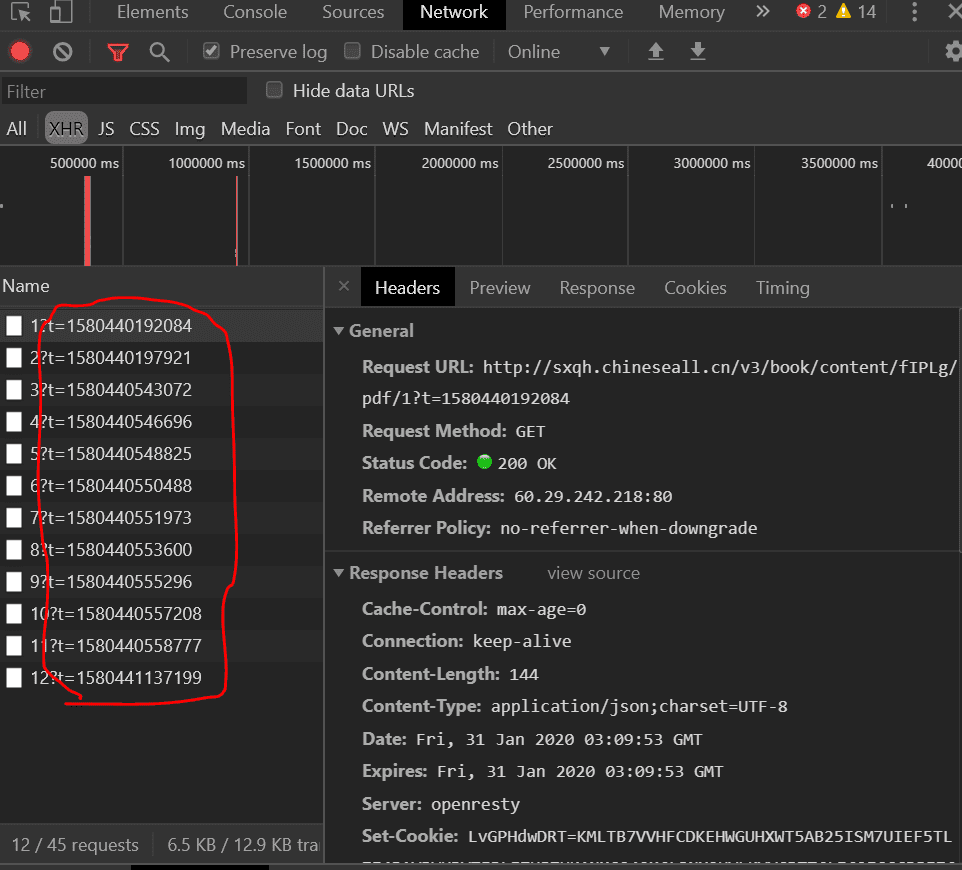
我们观察到每一页 pdf 的 url 都有一个变化的参数 t,在构造 url 时必须带上它,其他参数就没有了,目测 t 是时间戳:
参数 t 生成
时间戳我们可以用 python 的 time 模块生成:
import time
t = time.time()

但我们观察发现,与 t 有些不一样,它有小数,而且长度与 t 长度不一样,我们需要处理一下使其长度与 t 一样:
t = int(t * 1000)
这样处理后,得到的与实际的 t 长度一样了,但我们使用的 int() 函数,它是直接把小数点后面砍掉,不是四舍五入,我们不知道 t 到底有没有四舍五入,所以为了少写一些代码,一次性生成对的参数 t,我们直接使用 JavaScript 代码来生成,就绝对不会错了,我们创建一个名为 "1.js" 的文件,其中写入 JavaScript 生成时间戳的代码:
function t(){
var timestamp = new Date().getTime();
return timestamp
}
将其放在此项目的路径中。
当然我们还需要在 python 中调用 JavaScript 代码,使用 execjs 库,pip 安装即可,调用代码如下:
def get_t():
'''
执行 JavaScript 代码生成参数 t
'''
with open(r'1.js') as f:
s = f.read()
s = execjs.compile(s)
t = s.call('t')
return t
打开 1.js 文件,读取,使用 compile 方法编译,再使用 call 方法调用其中的 t 函数,最后返回 t。
生成了 t 后,剩下的爬虫逻辑就简单多了,构造 url,请求,下载,其中我们下载来的是图片,我们是保存为 pdf 文件的,图片请求返回后的格式是二进制的,使用 response.content 获取二进制信息。
pdf 合并
由于我们下载来后是一张张 pdf 文件:

我们需要合并,使用 PyPDF2 库,pip 安装即可,代码分成了几段,每一段都有对应的功能说明:
def merge_pdf(name):
'''
合并 pdf
'''
print('正在合并最终 pdf')
# find all the pdf files in current directory.
mypath = os.getcwd()
pattern = r"\.pdf$"
file_names_lst = [mypath + "\\" + f for f in os.listdir(mypath) if re.search(pattern, f, re.IGNORECASE)
and not re.search(name+'.pdf', f)]
# 对文件路径按页码排序
dic = {}
for i in range(len(file_names_lst)):
page = re.findall(r'(\d+)\.pdf', file_names_lst[i])[0]
dic[int(page)] = file_names_lst[i]
file_names_lst = sorted(dic.items(), key=lambda x: x[0])
file_names_lst = [file[1] for file in file_names_lst]
# merge the file.
opened_file = [open(file_name, 'rb') for file_name in file_names_lst]
pdfFM = PyPDF2.PdfFileMerger()
for file in opened_file:
pdfFM.append(file)
# output the file.
with open(mypath + "\\" + name + ".pdf", 'wb') as write_out_file:
pdfFM.write(write_out_file)
# close all the input files.
for file in opened_file:
file.close()
print('合并完成 %s' % name)
合并好后,我们手动删除一张张 pdf 留下最终合成的 pdf 即可:
end
这样我们就得到了一部电子书了,由于我们是串行爬取,意思就是单进程爬取,所以爬的速度有些慢,合并的速度根据页数来决定的,200 多页的 pdf 可能合并 5 分钟左右,小编下载此书时间如下:

如果想下载其他电子书,修改 url,循环页数,书名,记得登录即可。
登录,只需在请求头加上登录后的 cookie 即可。
完整代码
import execjs
import requests
import os
import time
import re
import PyPDF2
from fake_useragent import UserAgent
def get_t():
'''
执行 JavaScript 代码生成参数 t
'''
with open(r'1.js') as f:
s = f.read()
s = execjs.compile(s)
t = s.call('t')
return t
def get_url(p):
'''
生成对应页数的 url
'''
url = 'http://sxqh.chineseall.cn/v3/book/content/fIPLg/pdf/{}?t={}'
t = get_t()
url = url.format(p,t)
return url
def get_requests(url,p):
'''
请求 pdf url
'''
while True: # 请求失败,在请求一直成功为止
try:
headers = {'User-Agent' : UserAgent().random,
'Cookie' : 'JSESSIONID=DF207A8A8E8964D680DD733B533A6560; _Tvt5MJ89bV_=A9577ACE1D8E538E734AE16BA888C4EF45AB6CCC5272D0902251660D86210F41836CEE40CD0DB9C102CC0D54CCDD68B9258D339CE9A1B52AFB6C6D103E4BF00B565494A706613343CC75A04EDB72A342; LvGPHdwDRT=KMLTB7VVHFCDKEHWGUHXWT5AB25ISM7UIEF5TLZI4BAVPWHBVTFPLE7HJ7UKANMGS4OM6L3NX2UVLKVVCBTT6LI62IGGCDREZ66ICSI'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response
except:
continue
def download_pdf(text,p):
'''
下载为 pdf,名称为页码
'''
with open(str(p) + '.pdf','wb') as f:
f.write(text)
print('第 %s 页下载成功,共 233 页。' % str(p))
def merge_pdf(name):
'''
合并 pdf
'''
print('正在合并最终 pdf')
# find all the pdf files in current directory.
mypath = os.getcwd()
pattern = r"\.pdf$"
file_names_lst = [mypath + "\\" + f for f in os.listdir(mypath) if re.search(pattern, f, re.IGNORECASE)
and not re.search(name+'.pdf', f)]
# 对文件路径按页码排序
dic = {}
for i in range(len(file_names_lst)):
page = re.findall(r'(\d+)\.pdf', file_names_lst[i])[0]
dic[int(page)] = file_names_lst[i]
file_names_lst = sorted(dic.items(), key=lambda x: x[0])
file_names_lst = [file[1] for file in file_names_lst]
# merge the file.
opened_file = [open(file_name, 'rb') for file_name in file_names_lst]
pdfFM = PyPDF2.PdfFileMerger()
for file in opened_file:
pdfFM.append(file)
# output the file.
with open(mypath + "\\" + name + ".pdf", 'wb') as write_out_file:
pdfFM.write(write_out_file)
# close all the input files.
for file in opened_file:
file.close()
print('合并完成 %s' % name)
def main():
'''
主逻辑
'''
start = time.time()
for p in range(1,233): # 共有 446 也 pdf
url = get_url(p) # 构造这一页的 url
response = get_requests(url,p) # 请求 pdf 链接
download_pdf(response.content,p) # 图片下载为 pdf
end = time.time()
print(end - start) # 打印下载总共用时
merge_pdf(name='精通Scrapy网络爬虫') # 合并 pdf 文件,name 为电子书名
if __name__ == '__main__':
main()
