Start
我们这次的目标是某小说网的的小说章节的标题的爬取,我们使用正则来提取
https://www.jx.la/book/390/
分析
我们选中一个章节标题复制
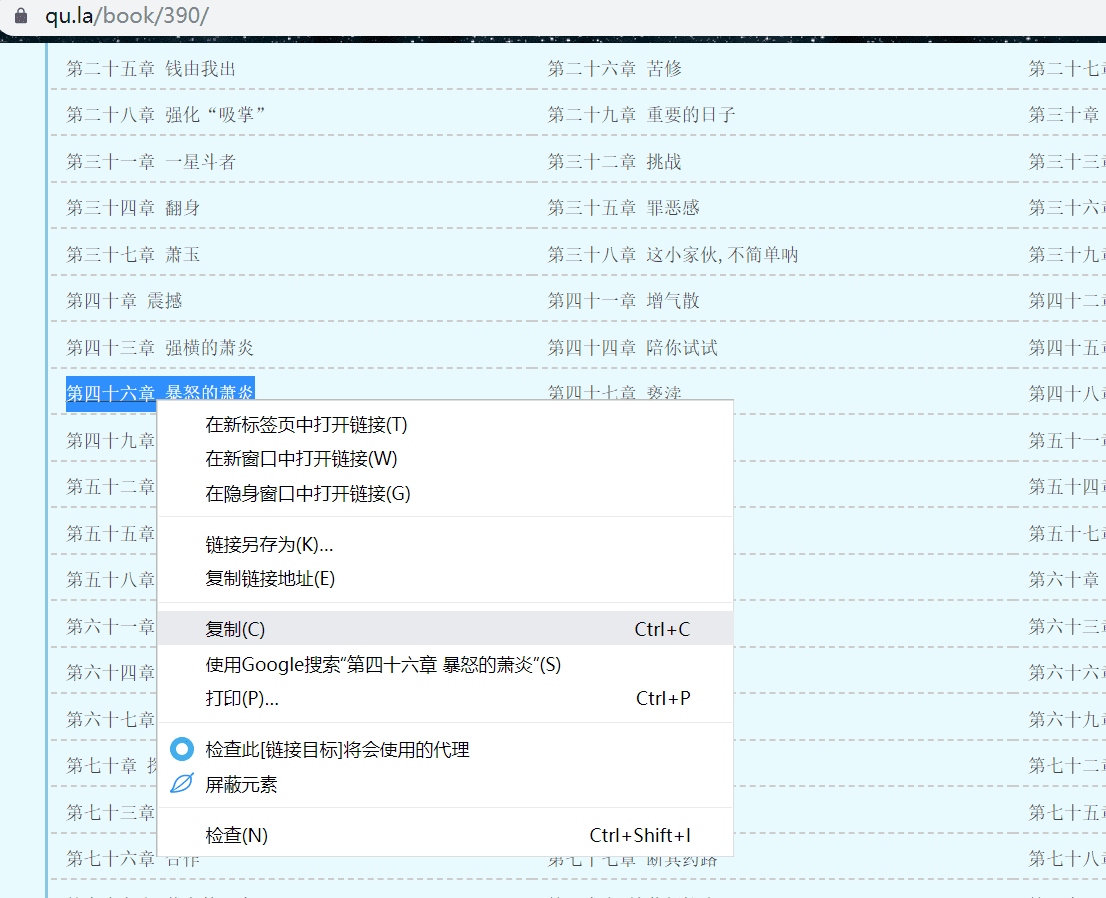
然后我们右键,查看源代码
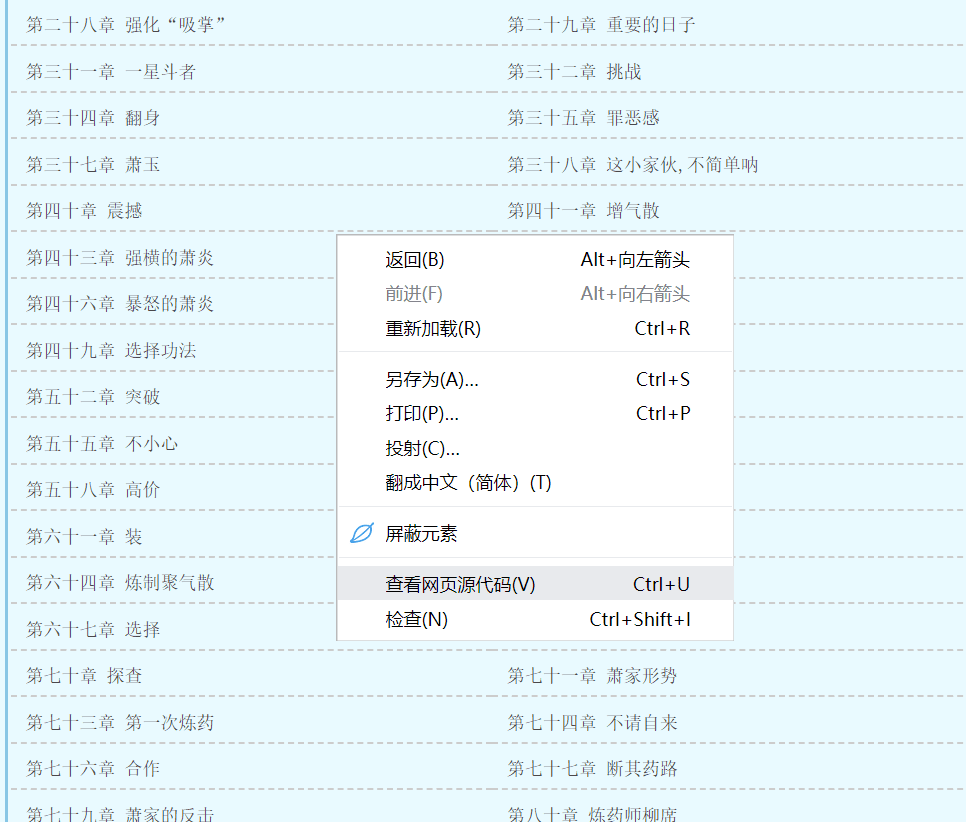

在网页源代码这页,按住 Ctrl + f 弹出搜索框,搜索刚刚的标题,其实就是定位我们要提取的元素位置
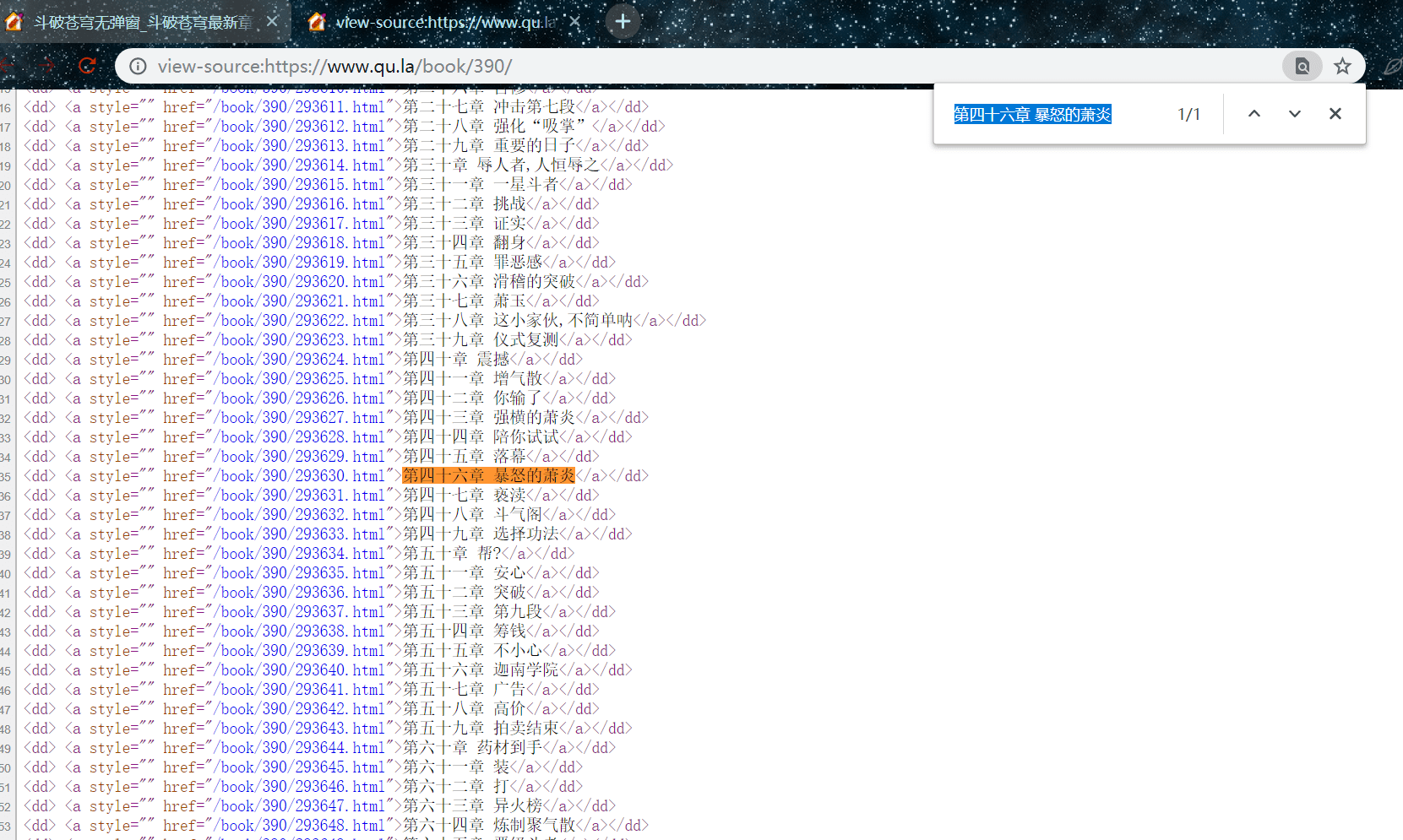
我们观察一下要提取的链接都是这种形式的:
<dd> <a style="" href="/book/390/293630.html">第四十六章 暴怒的萧炎</a></dd>
每一条这个标签都包含了一个标题信息,不同之处在于 href 属性的数字及标题,我们就需要从中提取标题
构造正则表达式:
pat = '<dd> <a style="" href="/book/390/\d+.html">(.*?)</a></dd>'
\d+:由于我们看到 每次 href 属性不同,所以需要匹配,\d 匹配一个数字,+ 匹配多个数字
.*?:匹配尽可能多的满足的字符,也叫贪婪匹配,我们这里标题是字符串,所以用它,当然也可以用它替换上面的 \d+
():匹配返回,如果在正则表达式中加上这个,那符合结果的会返回, \d+ 没有括号,因为我们不需要那些数字,.*? 这个匹配的是标题,我们需要所以加上括号返回
提取
titles = re.findall(pat,html,re.S)
我们使用 findall 方法
pat:正则表达式
html:网页源码,指的是 response.text
re.S:是一种匹配的模式,是指允许换行匹配,因为在构造正则时,网页源码可能换行了就需要它
它返回的是一个列表,包含了在此 html 源码中匹配的符合的结果
END
到这里,正则最常用的方法已经介绍了,下面给大家完整代码,在源码中我们有新使用了一个第三方库 fake_useragent 需要 pip 安装即可,它的作用是随机生成请求头,以后我们都使用它
完整代码
import requests
import re
from fake_useragent import UserAgent
def get_html(url):
'''
请求 html
:return:
'''
headers = {
'User-Agent' : UserAgent().random
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return
def get_info(html):
'''
提取文章标题
:param html:
:return:
'''
pat = '<dd> <a style="" href="/book/390/\d+.html">(.*?)</a></dd>'
titles = re.findall(pat,html,re.S)
for title in titles:
print(title)
if __name__ == '__main__':
'''
主接口
'''
url = 'https://www.qu.la/book/390/'
html = get_html(url)
if html == None:
print('请求失败!')
get_info(html)
结果截图

