Start
我们上一篇简单介绍了 ajax 技术是什么,这一篇我们以实际例子来具体示范一下,我们选取了 “今日头条” 爬取头条推荐栏的前十页的新闻标题
https://www.toutiao.com
翻页分析
打开网页,f12,f5 刷新,勾上 Preserve log,切换到 XHR 栏:
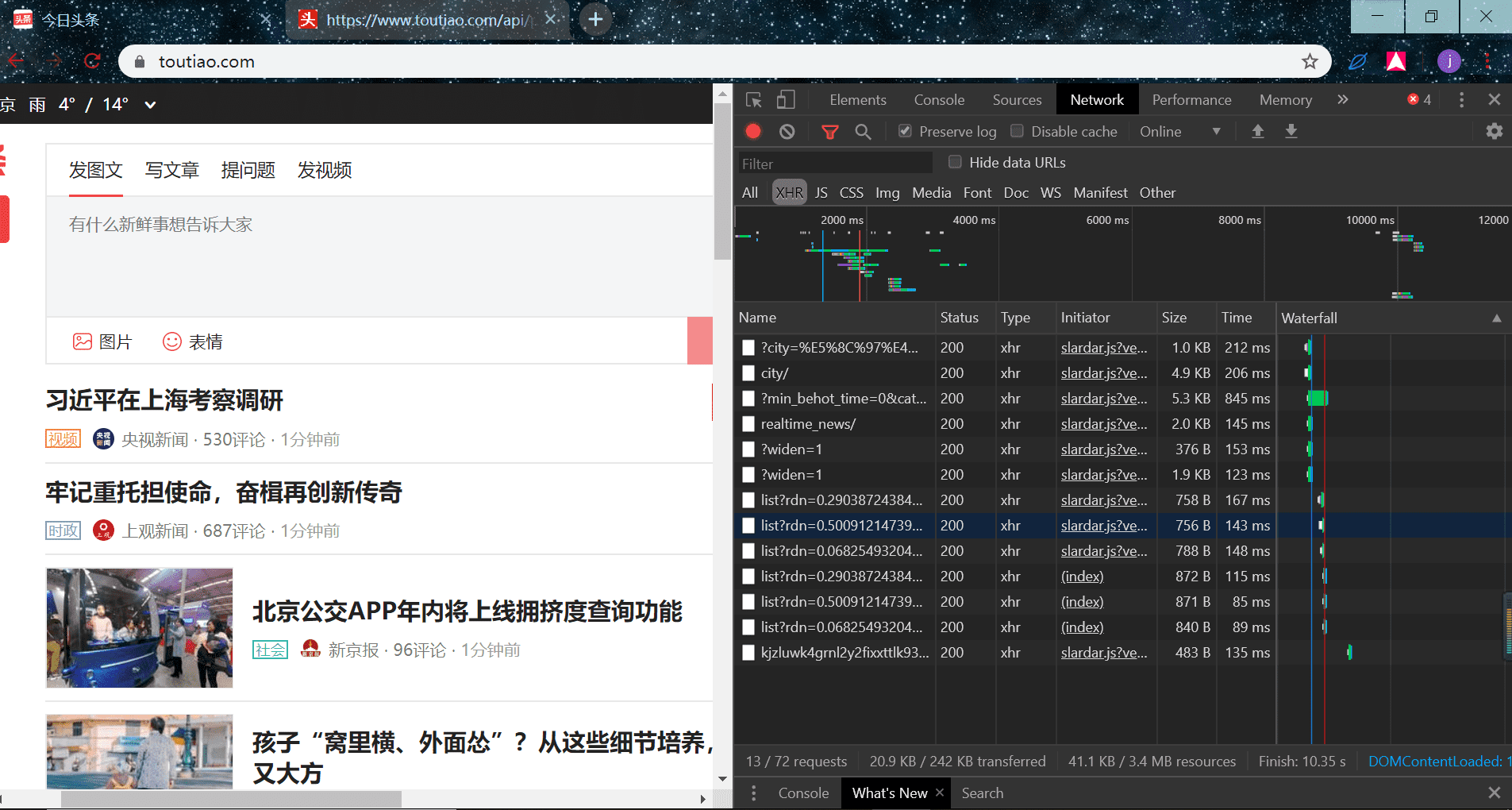
往下翻页会发现没有像淘宝那样的有页码,而是翻到最下面又会加载新的新闻出来,会看到抓到新的包,并且,我们的数据就在里面,每一个白色对应的叫包:
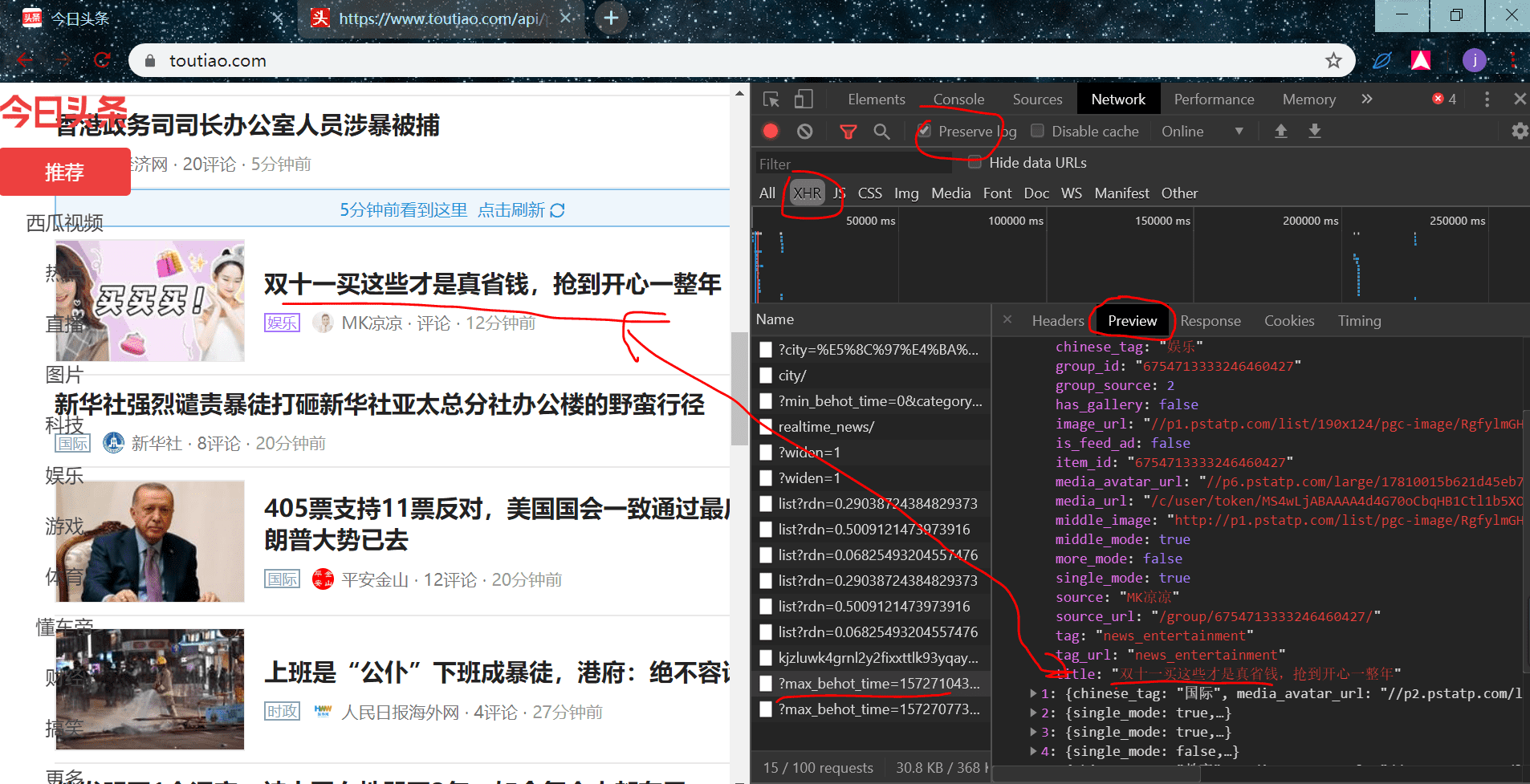
到这里我们就知道数据从哪里获取了,接下来我们就需要构造 url 去访问提取其中的数据就可以了,需要注意的是,我们只能从第二页开始,因为我们按 f12 后,是空白的,需要刷新一下,刷新后往下滑是从第二页翻页开始的,所以没有第一页的包
url 分析
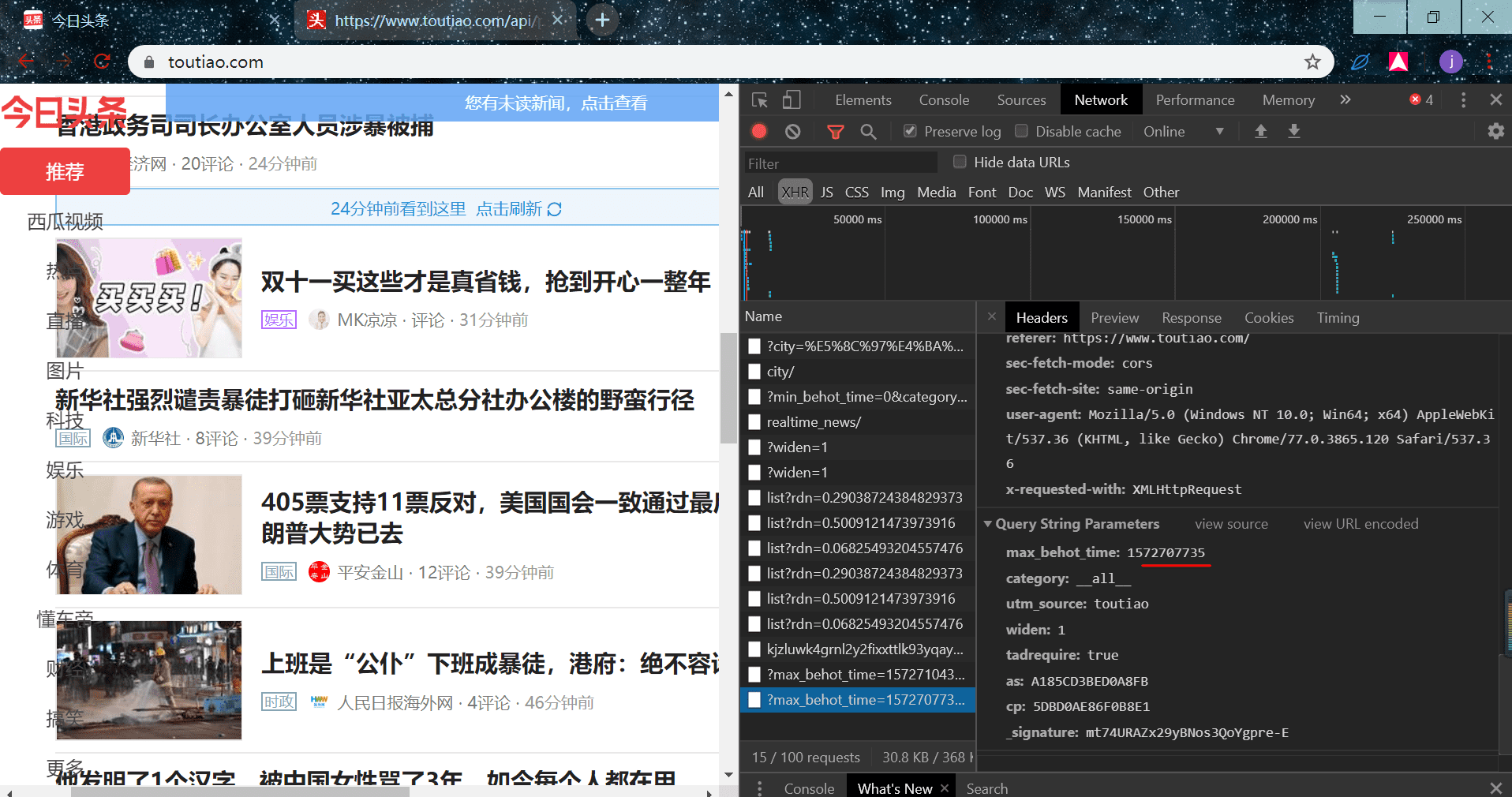
我们先找到 url 在哪里,切换到 Headers 标签栏:
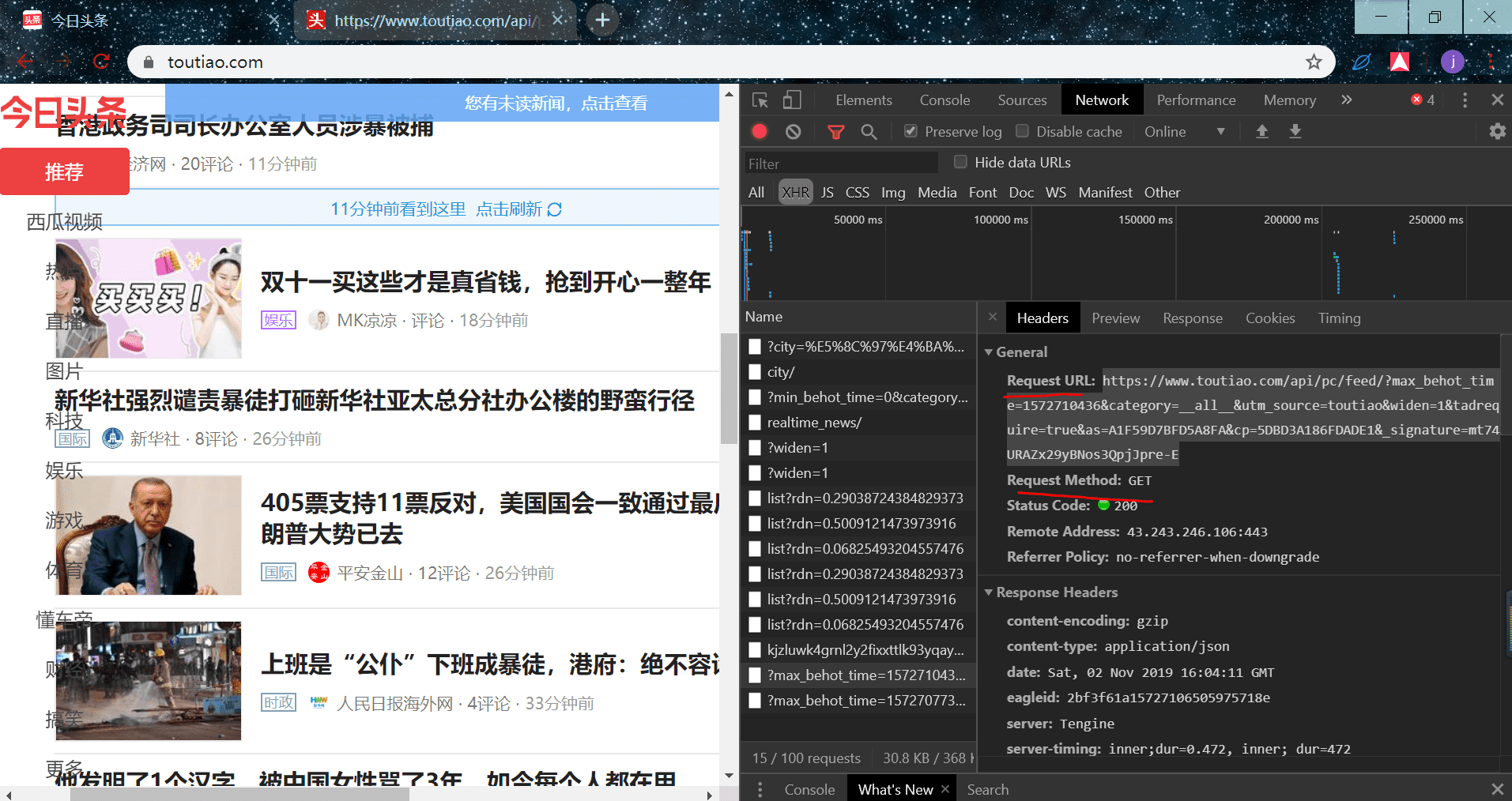
我们复制 url,并打开看到返回的 json 形式的数据,json 是一种数据格式,相当于 python 的字典:

我们可以删减一些参数可以发现并不影响数据返回,只有一个 max_behot_time 参数是影响每一页的参数:

但这样的形式不太好看,我们可以格式化一下,一般可以用 json 工具,可以在浏览器搜索 json 格式化在线工具,或其他插件都可以的,我们格式化后的图:
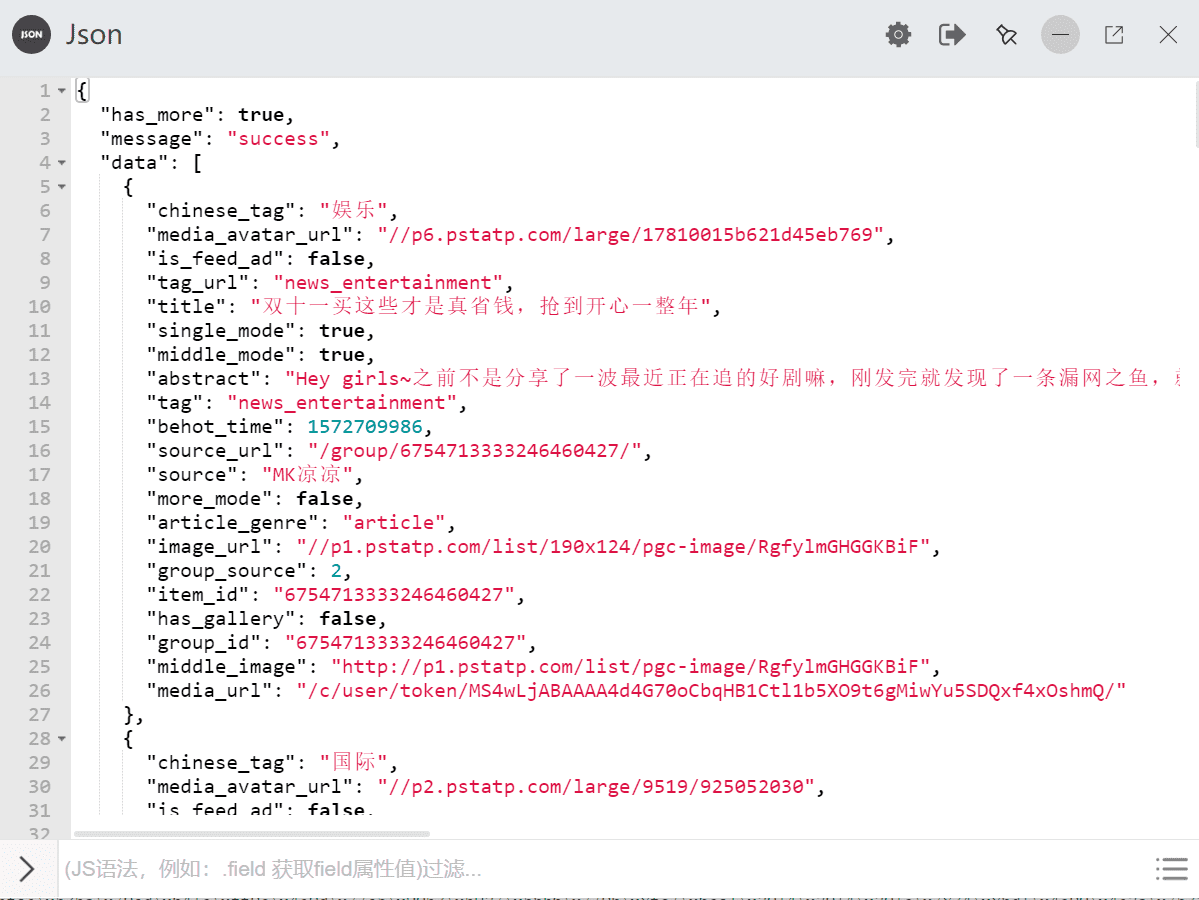
到这里,我们就可以根据此页的 url 提取此页的新闻标题了,但我们还没有构造下一页的 url,我们观察格式化的 json 有一个字段 max_behot_time 的值:
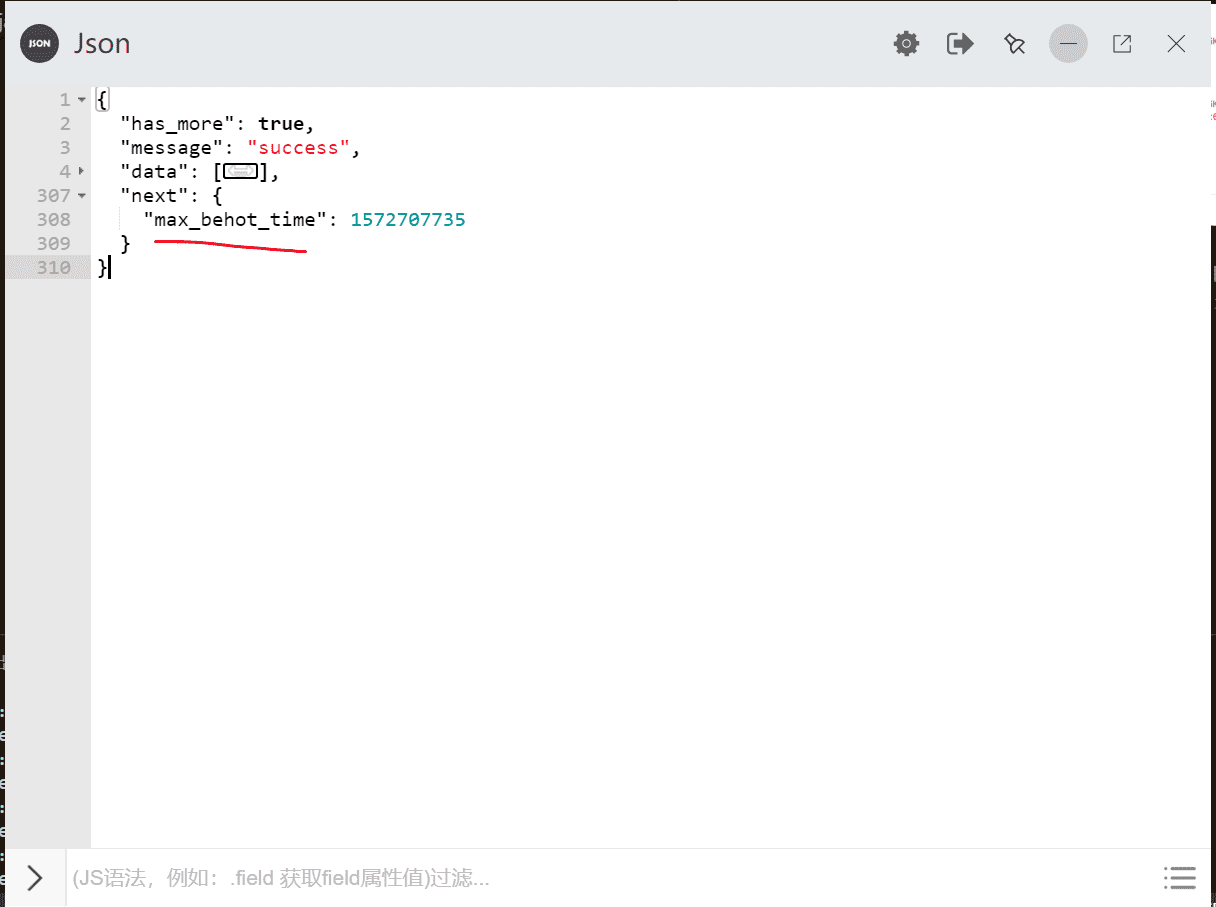
我们对比一下下一页的包的 max_behot_time 值,可以发现是一样的,由此判断这是构造下一页的实际参数:
END
到这里,就完成了异步加载抓包的过程,流程一般都是这样,在这里我们就不写代码了,只让大家明白,这个流程是怎么样的
因为想要爬取今日头条,那还得处理两个加密参数,这里不多说了,下一节,小编会找一个简单的例子,教大家爬取
