start
这一章节,我们来学习使用 selenium 库爬取数据。
selenium 是一个 web 自动化测试的库,现在也适用于爬虫,在爬虫方面,我们经常会遇到一些麻烦反爬,当访问某些网站,不是静态的,后端会加载许多相关的 JavaScript 文件来渲染,对于我们爬虫来说简单的渲染还好,复杂一点的就需要花时间了,说得直接 selenium 就是模拟人类的行为,去访问网站,提取数据,让我们的爬虫看起来像是人为的而不像机器,虽然使用它我们不需要怎么考虑它数据是怎么加载的,但唯一的缺点就是速度慢。
环境配置
在 python 中使用 selenium 需要下载一个驱动器去驱动浏览器,我们浏览器用谷歌浏览器,驱动和浏览器版本必须对应才行,要不然运行会报下面这错:
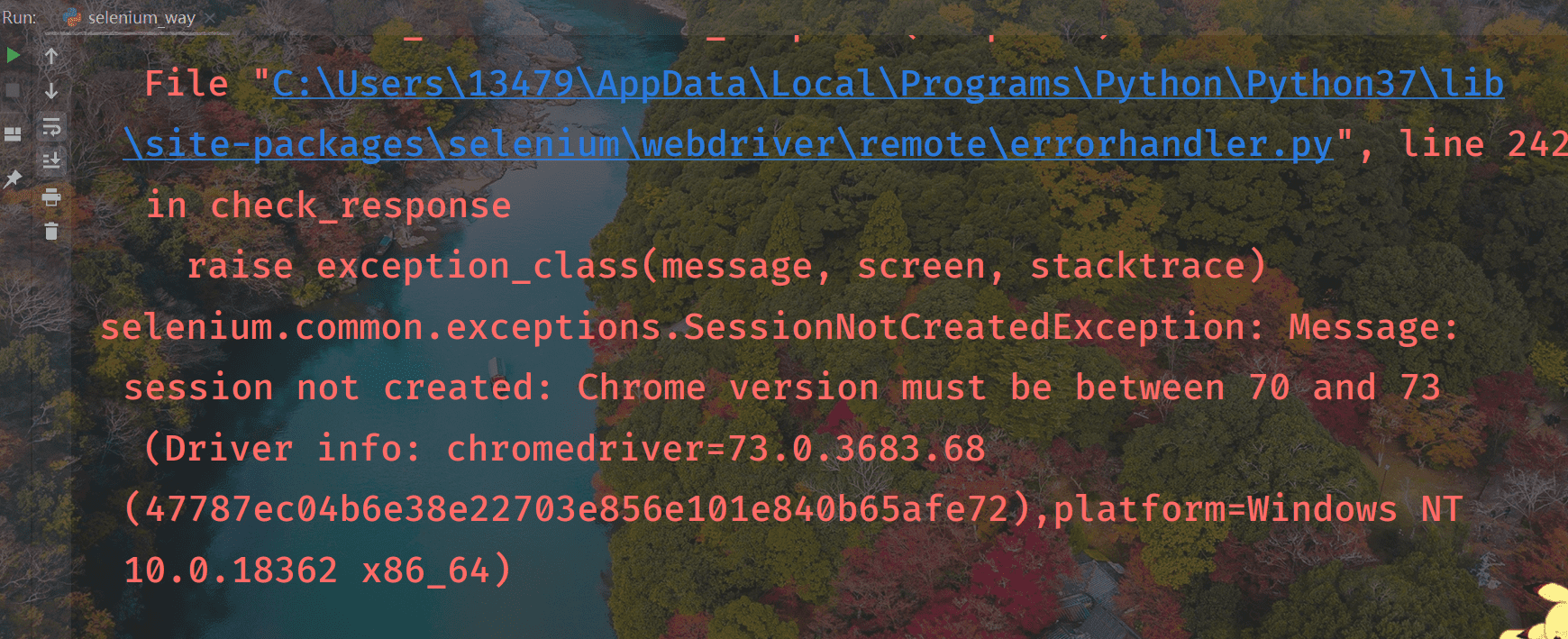
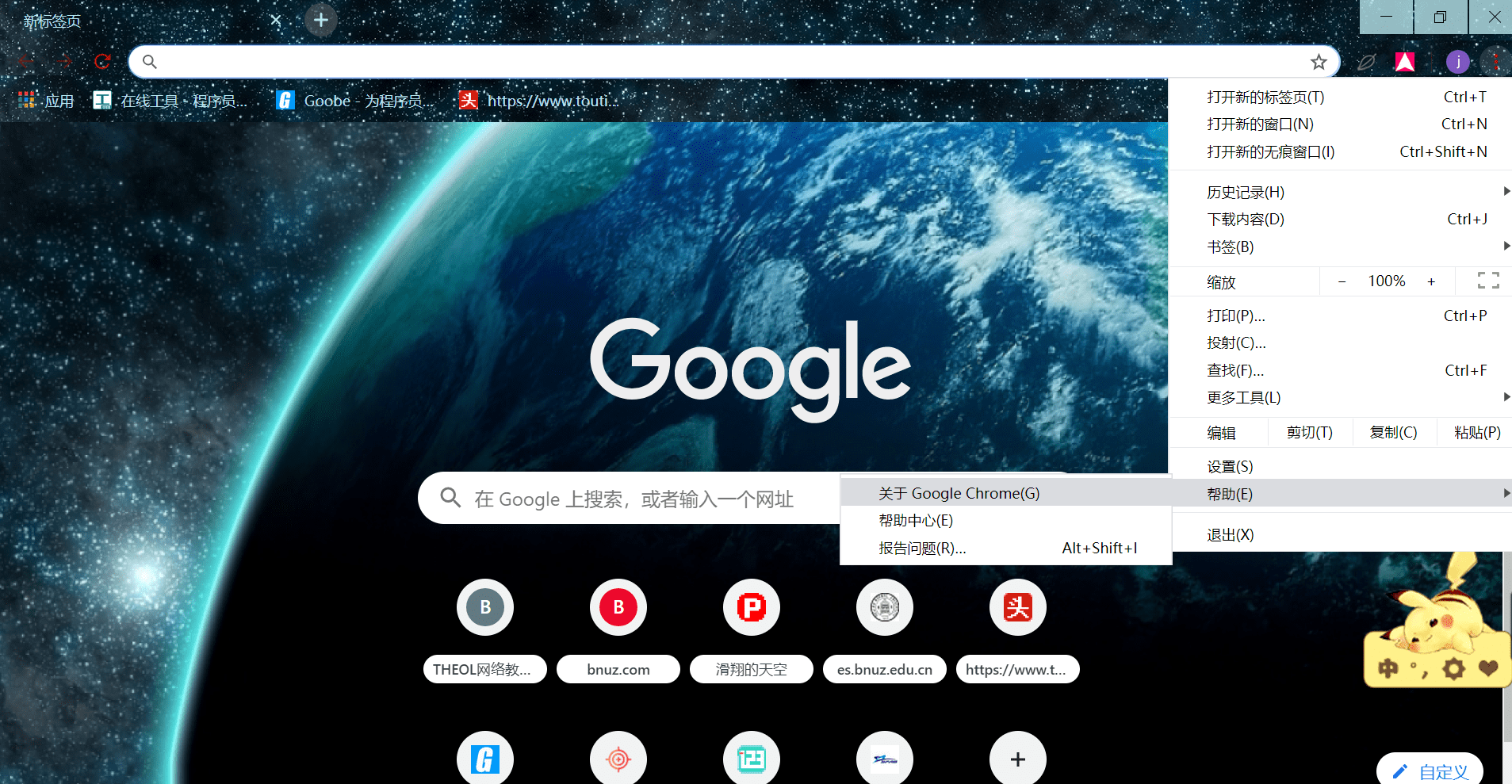
谷歌浏览器版本查看:
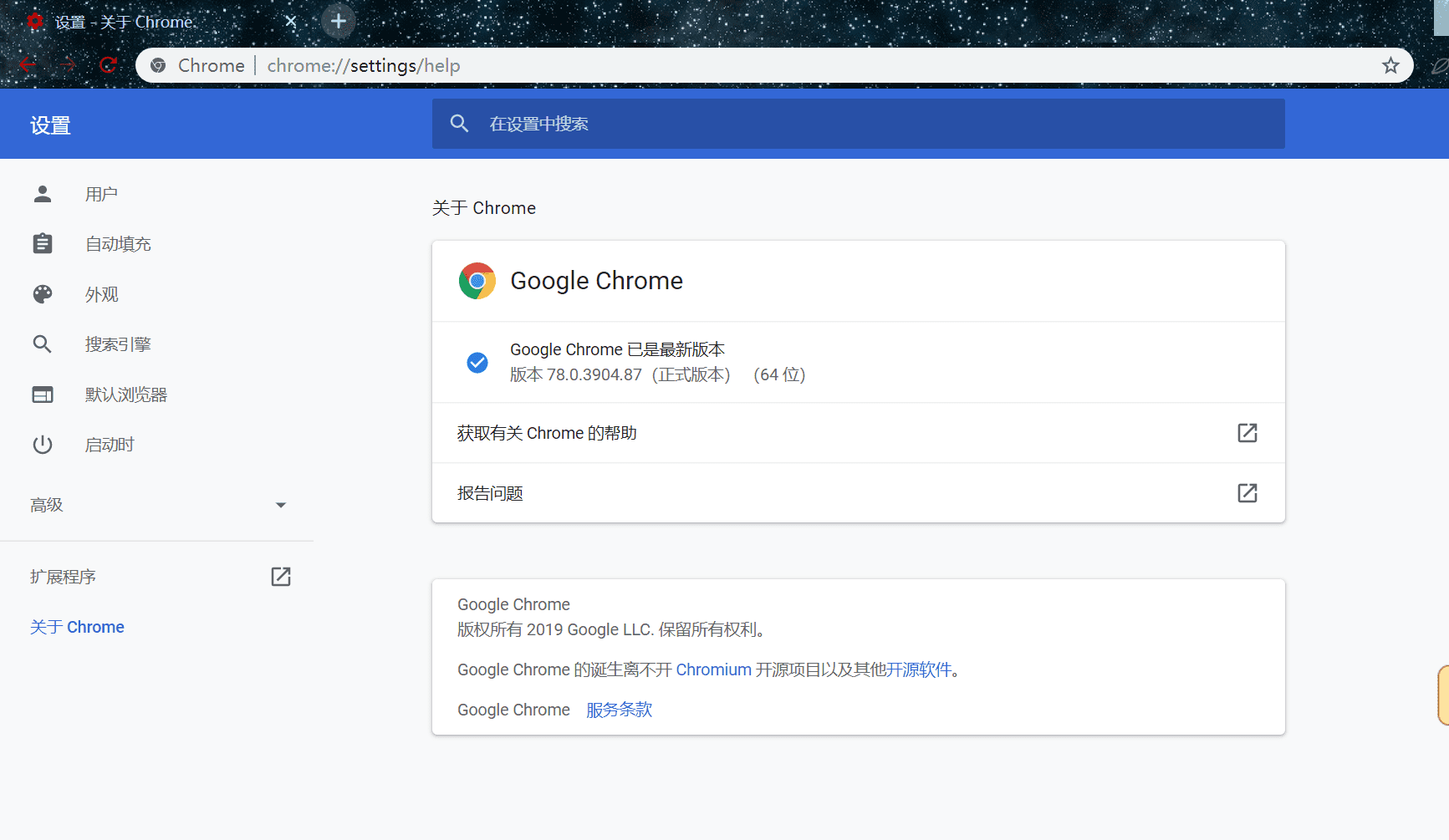
下载驱动:https://sites.google.com/a/chromium.org/chromedriver/downloads
选择和谷歌浏览器对应的版本,上面会写哪个版本对应哪个驱动:
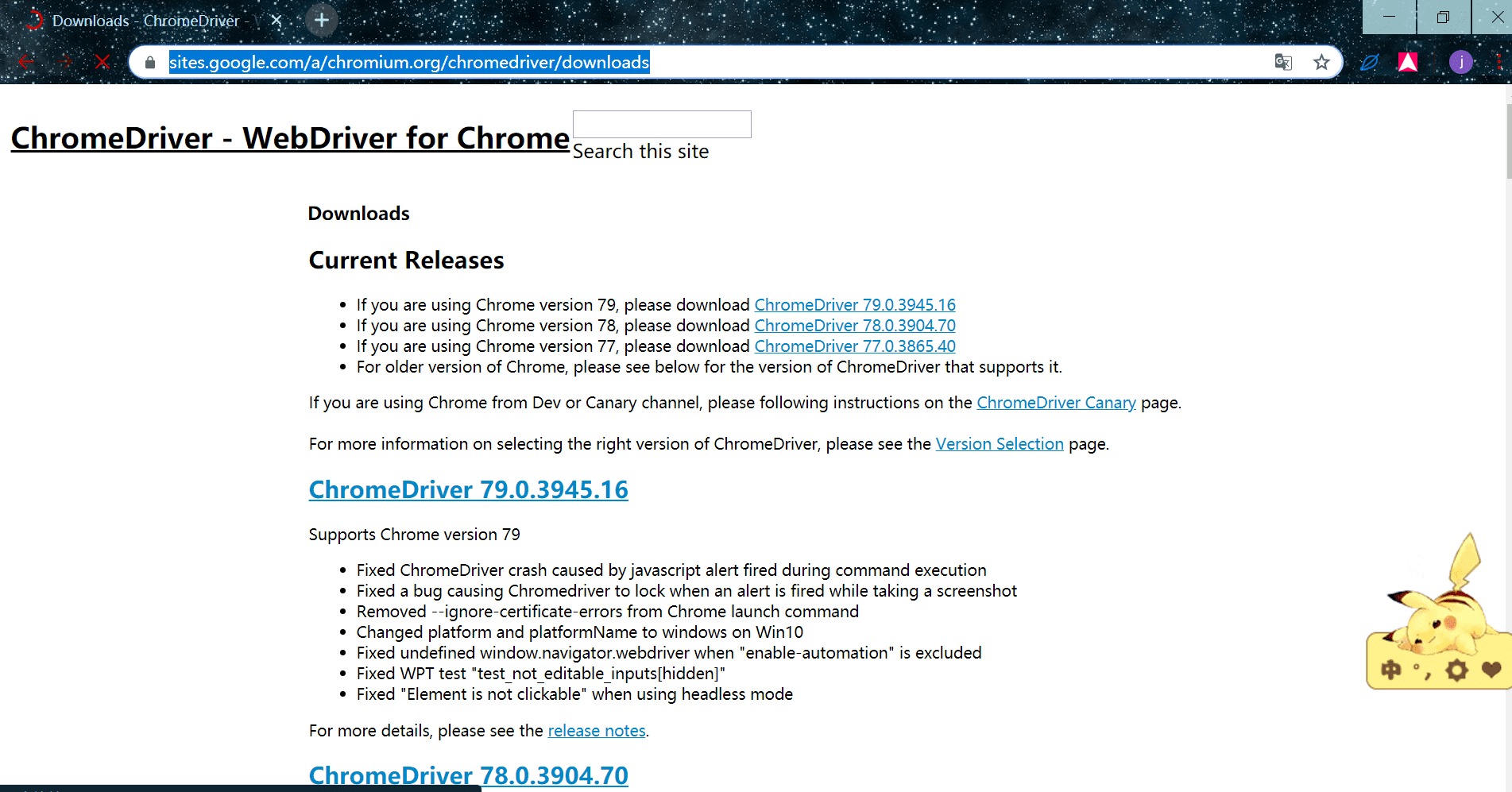
由于这是谷歌的域名,需要翻墙才能访问,所以我们找了个另外的链接供大家参考下载:
https://blog.csdn.net/cz9025/article/details/70160273
下载好后,是一个 exe 文件:
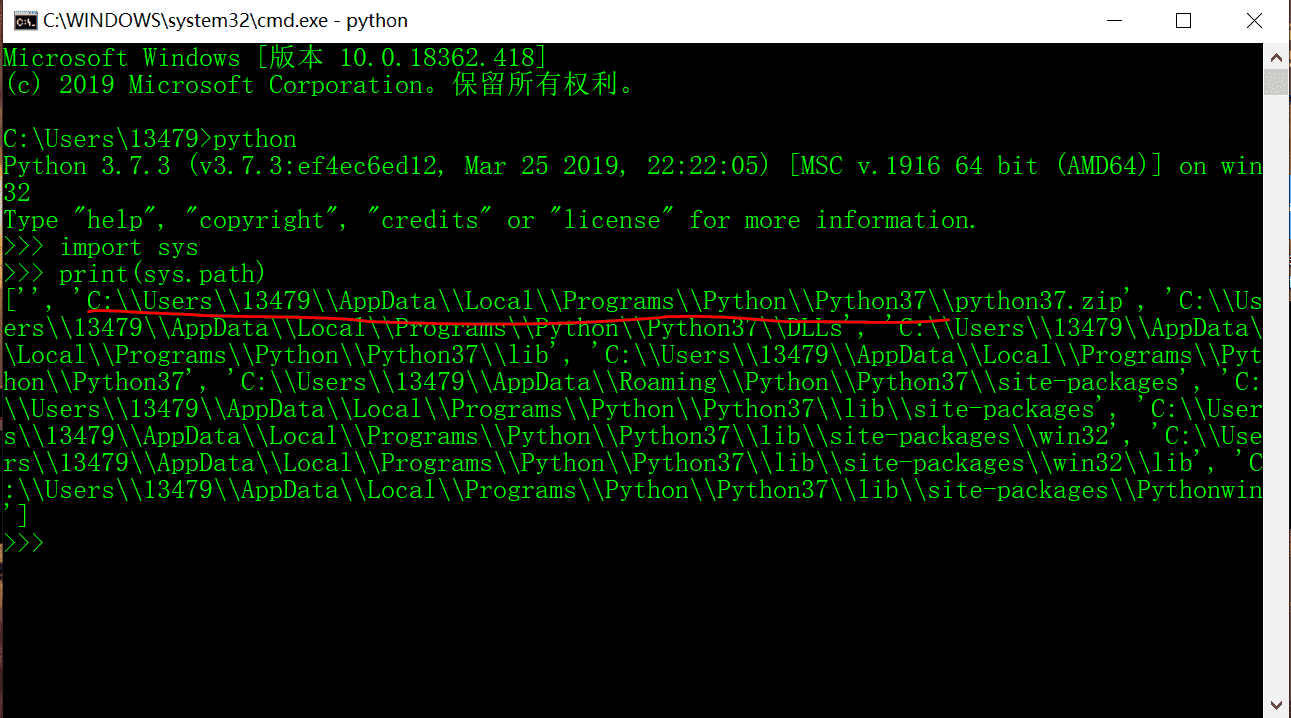
复制它,粘贴到你的 python 路径里面,先查看 python 路径:
import sys
print(sys.path)
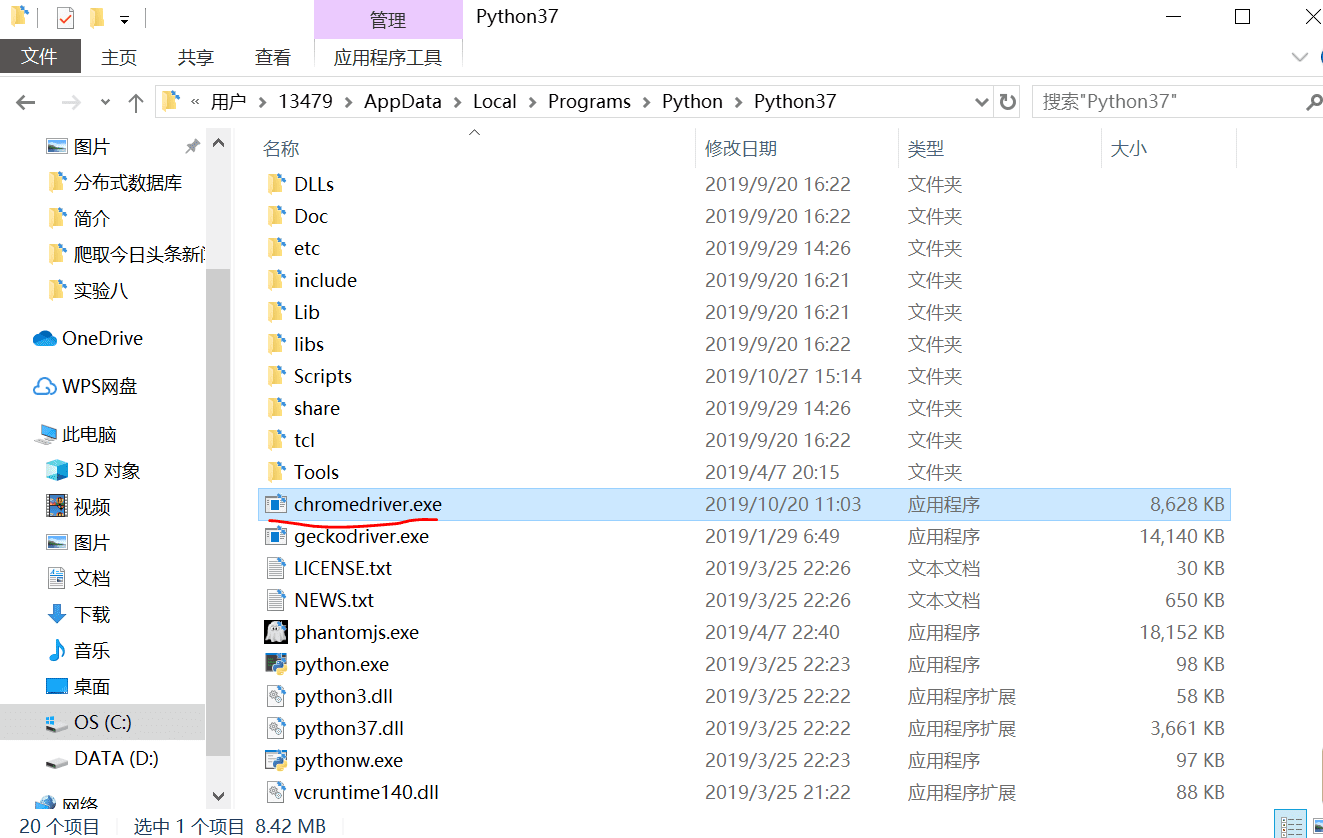
粘贴进去:
运行一下代码,能打开百度,表示成功:
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get('http://www.baidu.com')

