start
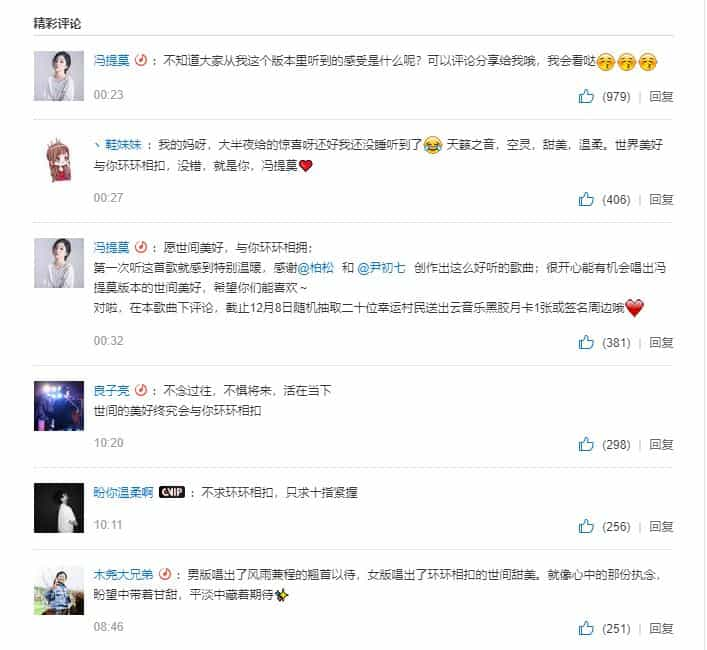
我们以网易云的 api 为例,爬取【世间美好与你环环相扣】歌曲的评论为例
网易云 api 接口:
https://mp.weixin.qq.com/s/ZxqRmTVKTcunMw023m5wug
目标:
https://music.163.com/#/song?id=1406211977
数据分析
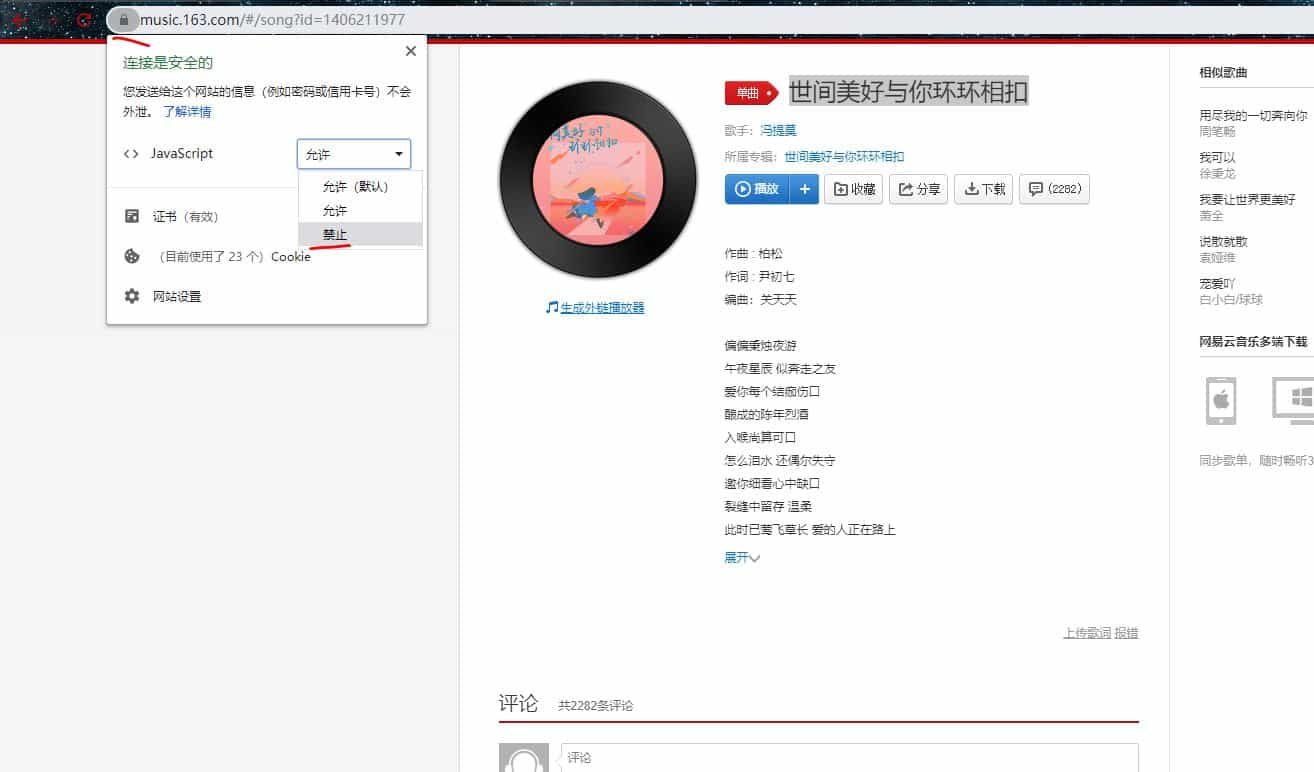
查看是否为 ajax 加载的,url 左侧有个锁,点击禁止 JavaScript 加载
禁止后,我们刷新网页可以看到如下,什么也没有,说明数据没有加载出来,哪些歌单是 ajax 动态加载的
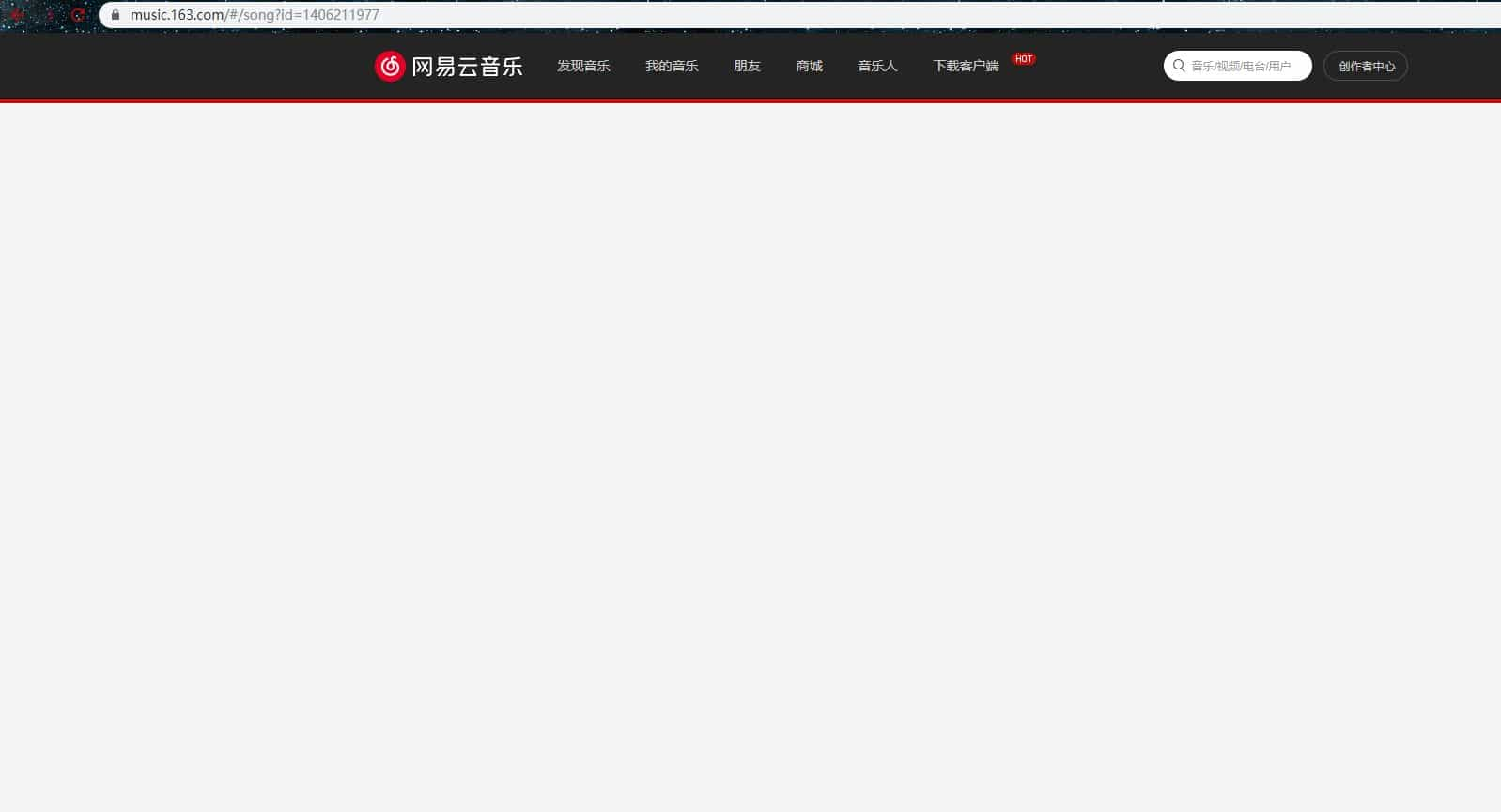
要去抓包分析再去提取数据好麻烦的,我们直接用 api 接口吧
api 接口
网易云音乐评论 api 接口,其中的歌曲 id 记得替换,id 在 url 可以看到的:
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit=20&offset=0
limit:返回数据条数(每页获取的数量),默认为20,可以自行更改
offset:偏移量(翻页),offset需要是limit的倍数
type:搜索的类型
举例,比如limit设置为10,则第一页,第二页分别为:
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=0
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=10
返回的数据格式为 json,就是 python 中的字典,需要注意的是通过此接口获取的评论数量最多2万条。
格式化 json 数据,可以搜索在线工具【json格式化】,有很多工具的
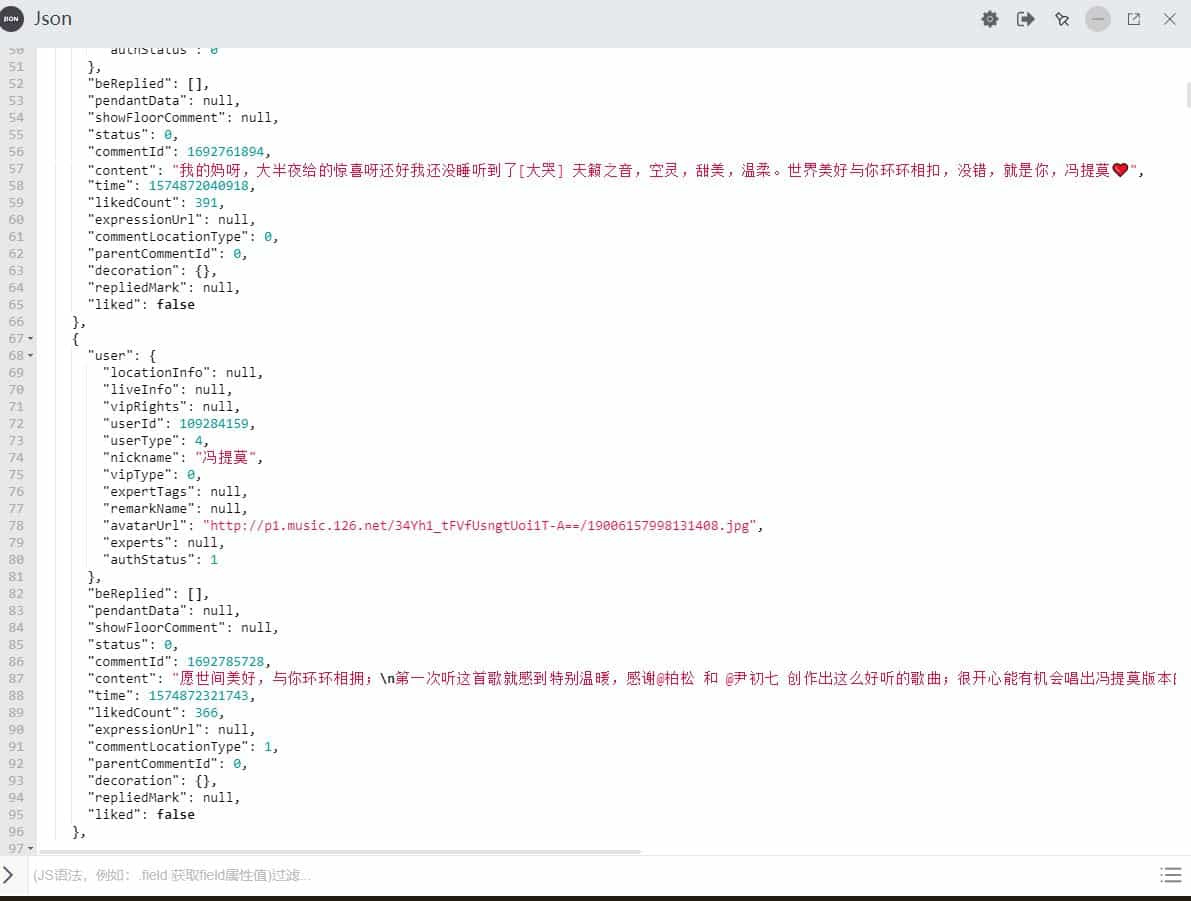
可以看到评论数据在 content 中
提取数据
小编只提取一页的评论,提取多页可列表推导出多页 url
import requests
import json
import jsonpath
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_1406211977?limit=20&offset=0'
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'
}
response = requests.get(url,headers=headers)
json_txt = json.loads(response.text)
names = jsonpath.jsonpath(json_txt,'$..content')
for name in names:
print(name)
其中使用了 jsonpath 库,和 json 库
json.loads(response.text):返回的是 json 格式数据,所以我们需要转换成 python 的字典
jsonpath.jsonpath(json_txt,'$..content'):提取字典中键为 content 的对应的所有值,不需要管路径,不需要管是怎么嵌套的了,返回的是列表