好啦好啦,那我们来拉开我们的爬虫之旅吧~~~
这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的。
环境配置
在此之前需要下载一个谷歌浏览器,下好后由于谷歌搜索是需要翻墙的,可设置打开网页为百度来使用
我们用到的是 bs4,requests 这两个库来提取,这是简称,全称是 BeautifulSoup 库。中文名也叫“美丽的汤”,安装也很简单。
打开 cmd 命令行(win + r),输入 pip install bs4 完成安装,如下图:

requests 库同样,pip install requests
可能遇到的安装错误
如果执行 pip install bs4 后报错为“pip 不是可执行的命令”
这是因为没有把 pip 的路径加入“环境变量”,加入环境变量即可
构造请求网址
我们是爬取酷狗音乐TOP500 的‘音乐名’,‘歌手’,‘歌名’,‘播放时间’这几个数据网址如下:
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
打开后只能看到前 22 名的数据,如下:

网址也叫 url,唯一资源定位符,我们观察 url 如下几个字段:
https:传输协议,一般都是 http 或 https
www.kugou.com:为域名
yy/rank/home/abs:为域名下的子网页
.html:代表此网页是静态的,后面会讲
?:问好后面的一般都是一些请求参数
我们可以看到,其中有一个 1-8888 这个参数,打开上述网址后我们只能看到前 22 首歌,想继续查看后面的歌曲就得翻页,就像“淘宝”那样查看下一页商品需要翻页,这里也是一样的道理,把 1-8888 改成 2-8888 ,就会看到下一页的 22 首歌,如下:
我们翻到第 500 首音乐那一页,可以看到页码如下有 23 页:
到这里我们我们需要提取的数据就知道在哪里了。
在知道了有多少页以及 url 的含义后,通过以下代码构造所有的 url:
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'
.format(str(i)) for i in range(1, 24)]
构造请求头
什么是请求头?
别人网页区别是人还是机器访问的一种手段,我们设置请求头为浏览器的请求头,对方就会认为我们是人为的访问,从而不会反爬,当然这只是最简单的一种防反爬的手段,一般我们都会带上,代码如下:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
这并不是一个一个手敲的!!!
我们来看看它在哪里,按 F12 出现开发者工具,再按 F5 刷新出现如下图:
按照红线提示,找到 user-agent
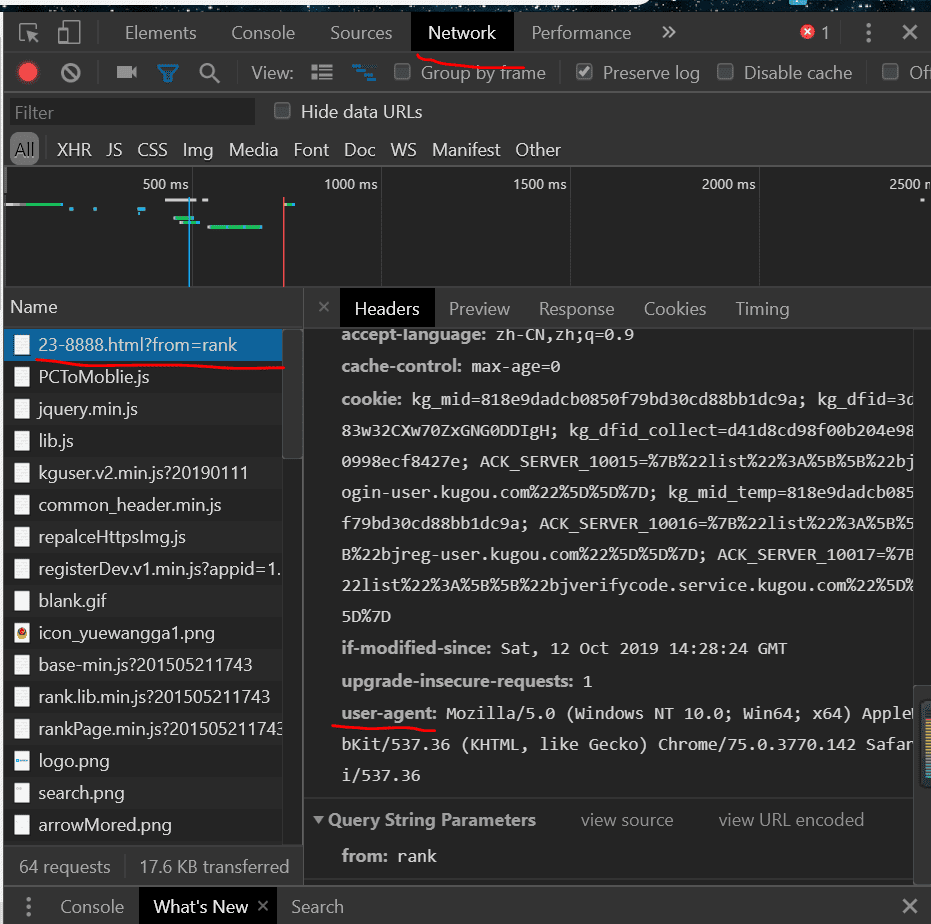
最后复制粘贴得到上面的代码
请求访问网页
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return
response = requests.get(url, headers=headers)
使用 requests 库的 get 方法,去访问网页,第一个参数为网址,第二个参数为请求头,请求结果赋值给变量 response,其中里面有很多结果,状态响应码,网页源码,二进制等
response.status_code == 200
调用请求结果 response 中的 status_code 查看请求状态码,200 代表请求成功,就返回,否则返回一个 None,状态码一般有 2xx,4xx,3xx,5xx,分别代表请求成功,客户端访问失败,重定向,服务器问题。
return response.text
返回响应结果的 text,代表返回网页 html 源码
解析网页
在上面返回了一个 response 后,我们需要解析网页 html 源码,需要结构化,便于提取
html = BeautifulSoup(html)
提取数据
我们来提取排名,鼠标放在排名这个元素这里,右键检查:
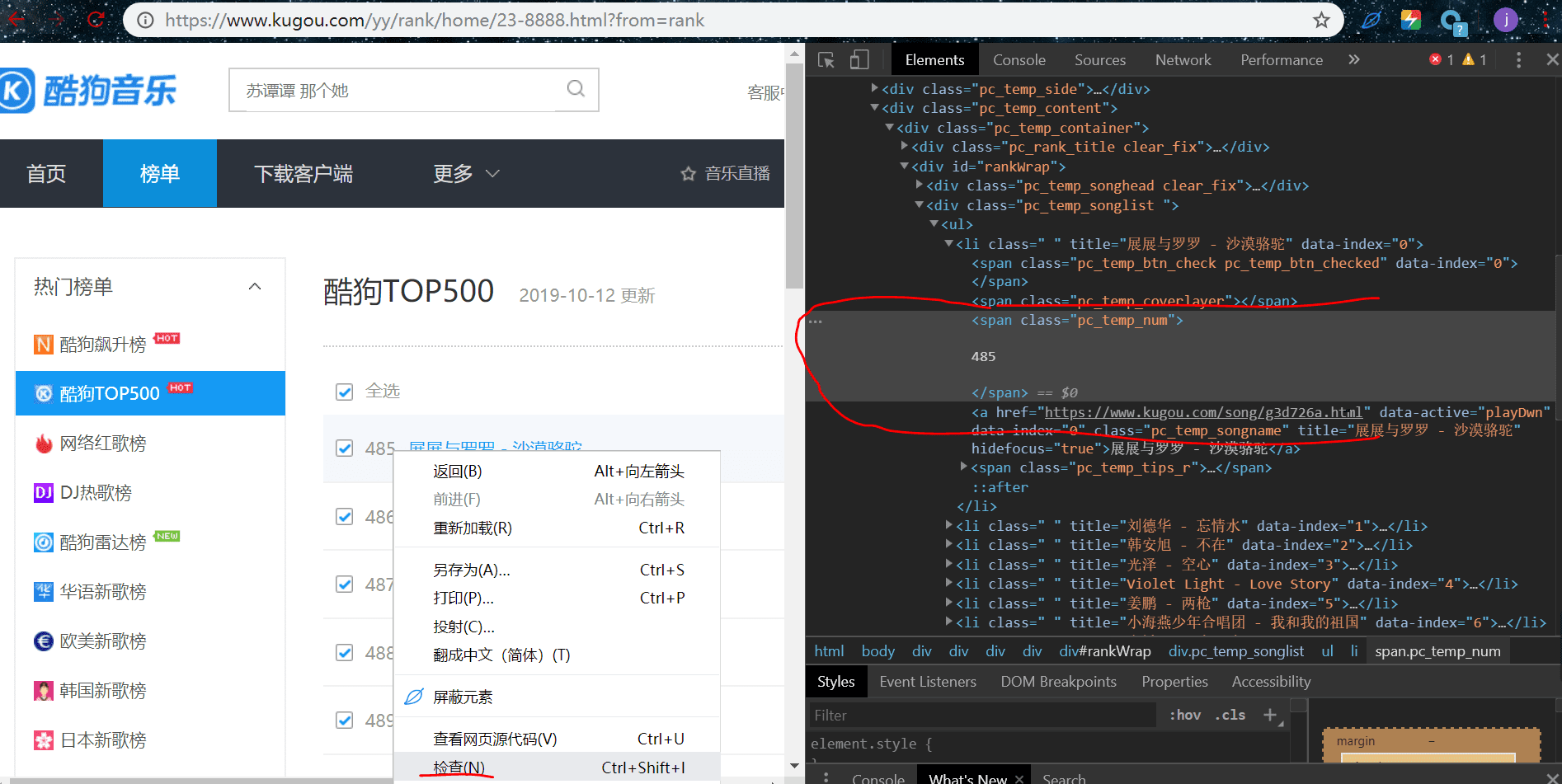
在右边可以看到一串源码。其中有个高两条,就是刚刚那个排名的元素,右键按照提示选择然后复制过去,其中 li:nth-child(1) 需要改成 li,因为 nth-child(1) 是获取 li 标签下的一条数据,我们是要获取这一页的所有排名
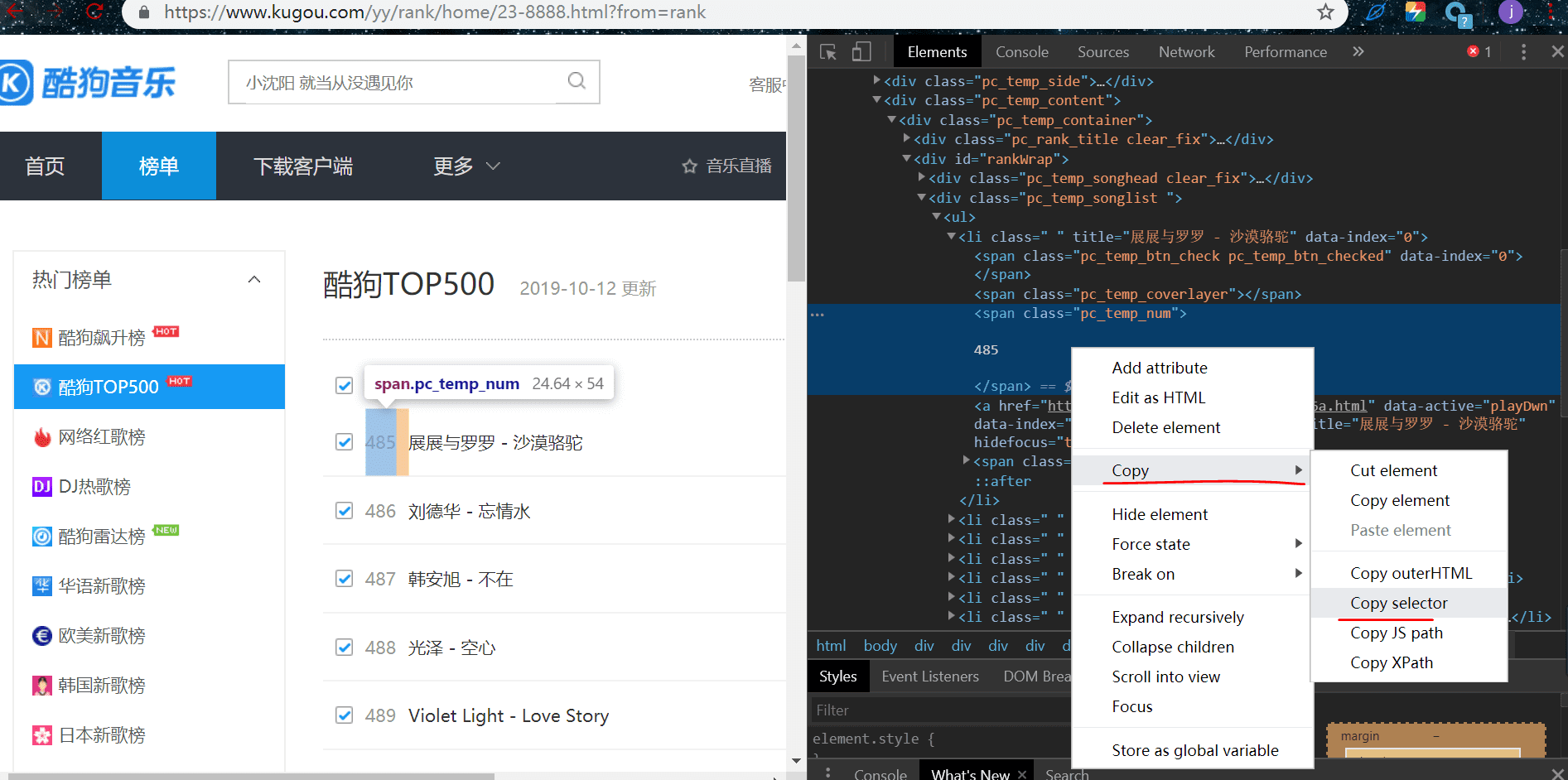
# 排名
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
同样的方法提取歌手歌名,播放时间
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
获得数据
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
用了 zip 函数,意思是把对应的排名,歌名歌手,播放时间打包,可以这样理解 zip 函数的结果是一个列表 [(排名,歌手歌名,播放时间),(排名,歌手歌名,播放时间)。。。。。]
每一次循环的 r,n,t 一次对应元组中的元素
get_text()
我们提取到的是这个数据所在的标签信息,并不是实际数据,所以需要使用 get_text() 获得实际数据
.replace('\n','').replace('\t','').replace('\r','')
去掉实际数据中多余的字符串
最后把数据打包成字典打印
END
到这里我们的关键步骤就完成了,大家好好理解一下,很容易的。
在这里说一下,这种提取方式是不会常用的,因为效果很不健壮,可能过几天被人网页改了改结构,就不能使用了,这里只是让大家初步了解一下爬虫的大致提取流程,后面会使用其他更健壮的方法的。
最终代码
import requests
import time
from bs4 import BeautifulSoup
def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return
def get_infos(html):
'''
提取数据
'''
html = BeautifulSoup(html)
# 排名
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
# 打印信息
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
data = {
'排名': r,
'歌名-歌手': n,
'播放时间': t
}
print(data)
def main():
'''
主接口
'''
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'
.format(str(i)) for i in range(1, 24)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1)
if __name__ == '__main__':
main()
{'排名': '1', '歌名-歌手': '小阿七 - 那女孩对我说 (正式版)', '播放时间': '4:28'}
{'排名': '2', '歌名-歌手': 'en - 嚣张', '播放时间': '4:14'}
{'排名': '3', '歌名-歌手': '宝石Gem - 野狼disco', '播放时间': '3:59'}
{'排名': '4', '歌名-歌手': '阿悠悠 - 责无旁贷', '播放时间': '3:28'}
{'排名': '5', '歌名-歌手': '常艾非 - 刺心', '播放时间': '3:27'}
{'排名': '6', '歌名-歌手': '音阙诗听、赵方婧 - 芒种', '播放时间': '3:36'}
{'排名': '7', '歌名-歌手': 'Uu - 那女孩对我说 (完整版)', '播放时间': '4:40'}
{'排名': '8', '歌名-歌手': '于嘉乐 - 逃爱', '播放时间': '4:02'}
{'排名': '9', '歌名-歌手': '崔伟立 - 酒醉的蝴蝶', '播放时间': ...
