start
这一节我们来讲解多进程
电脑一般都有多个 cpu(中央处理器),就是计算处理的核心,程序需要靠它运行,每台计算机一般都配有多个 cpu,而通常我们只用了一个 cpu,如果都使用的话,效率会提高
在爬虫中,我们之前的都是一个进程,例如有10条 url,之前都是只用了一个 cpu,顺着从前往后,一个一个来请求访问的,也叫串行爬虫
当 url 少时,无所谓,因为程序运行很快的,比较多时,可能就力不从心了,可以用多进程,开启多个 cpu 同时请求多个 url,提高效率
创建多进程
"""
Pool 可以提供指定数量的进程供用户调用,默认大小是 CPU 的核数。但有新的请求提交到
Pool 中时,池还没有满,就会创建一个新的进程用来执行该请求;如已达到最大数,就会等待
知道有进程结束,才会创建新的进程来处理他
"""
from multiprocessing import Pool
import os,time,random
def run_task(name):
print('Task %s (pid = %s) is running ...' % (name,os.getpid()))
time.sleep(random.random() * 3)
print('Task %s end.' % name)
if __name__ == '__main__':
print('Current process %s.' % os.getpid()) # os.getpid() 获得进程 id
p = Pool(processes=3)
for i in range(5):
p.apply_async(run_task,args=(i,)) #添加进程任务,i 为传进去的进程任务的参数
pass
print('Waiting for all subprocesses done...')
p.close() #不再添加新进程
p.join() #等待所有子进程执行完毕,调用之前必须先调用 close(),针对 Pool 对象
print('All subprocesses done.')
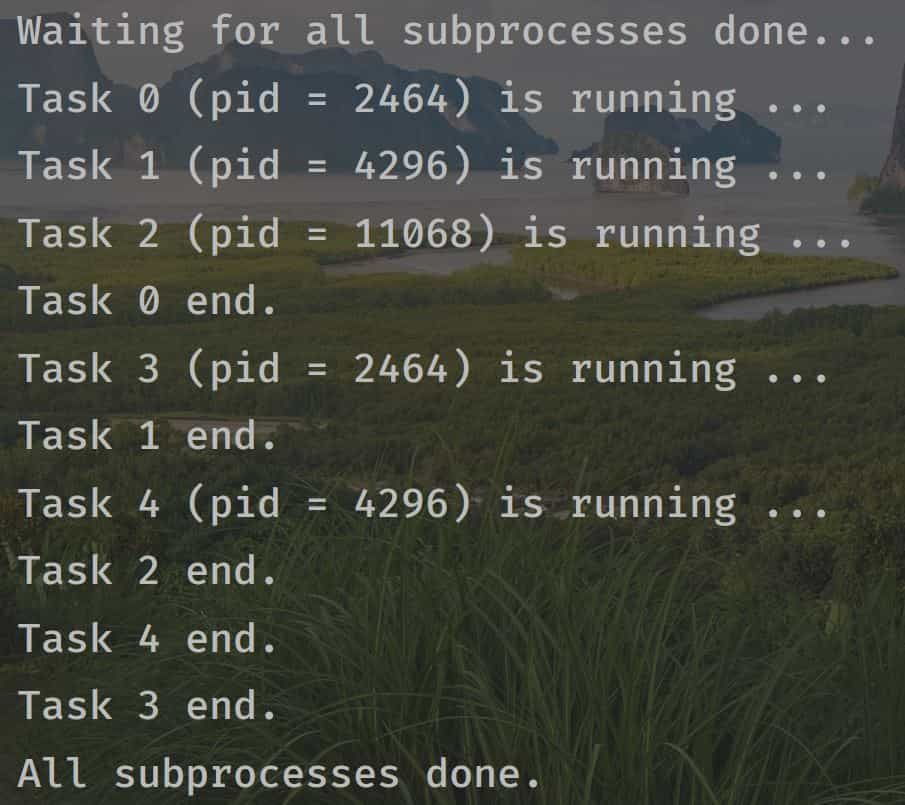
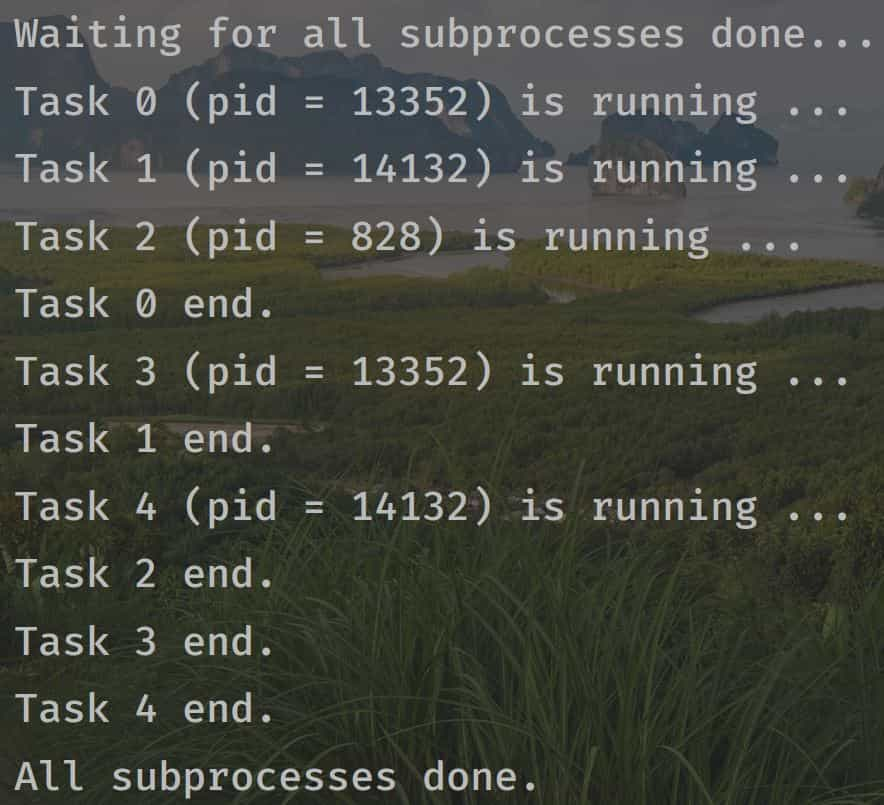
在上面的代码中,我们创建了3个进程,在爬虫中照着这个流程创建多进程即可,关键地方都写了注释
3个进程的运行可以看到每次结果都是开始创建的时候没区别,创建好后去执行任务就变成无序的了,因为没有优先级,谁先完成谁就等待其他进程完成