start
这一章我们来爬取今日星座运势,采用 4 中方式带大家复习一下
没错 4 种!!!bs4,lxml,正则,还有一种是 css 提取,我们先以 css 为例来示范
css 与 xpath 很像,xpath 表达式在程序运行时,会先翻译成 css 表达式,所以css 可以说是 xpath 的父亲吧,有些时候 xpath 表达式没写错,但就是提取不出来,这时候可能就需要切换用 css
https://www.d1xz.net/astro/Aries/
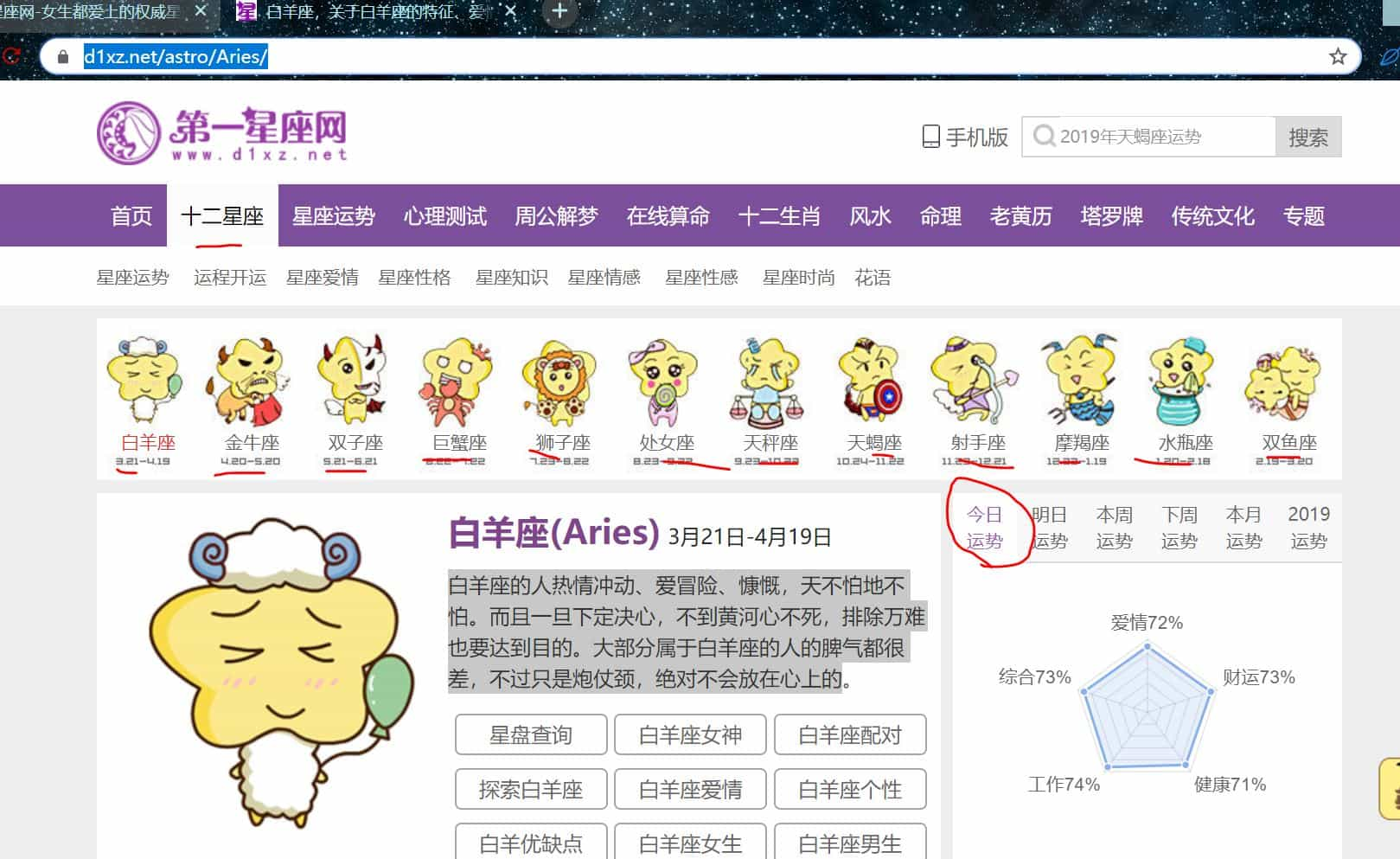
我们爬取 12 星座今日运势,如图:
包安装
pip install cssselect
确定网页是否静态
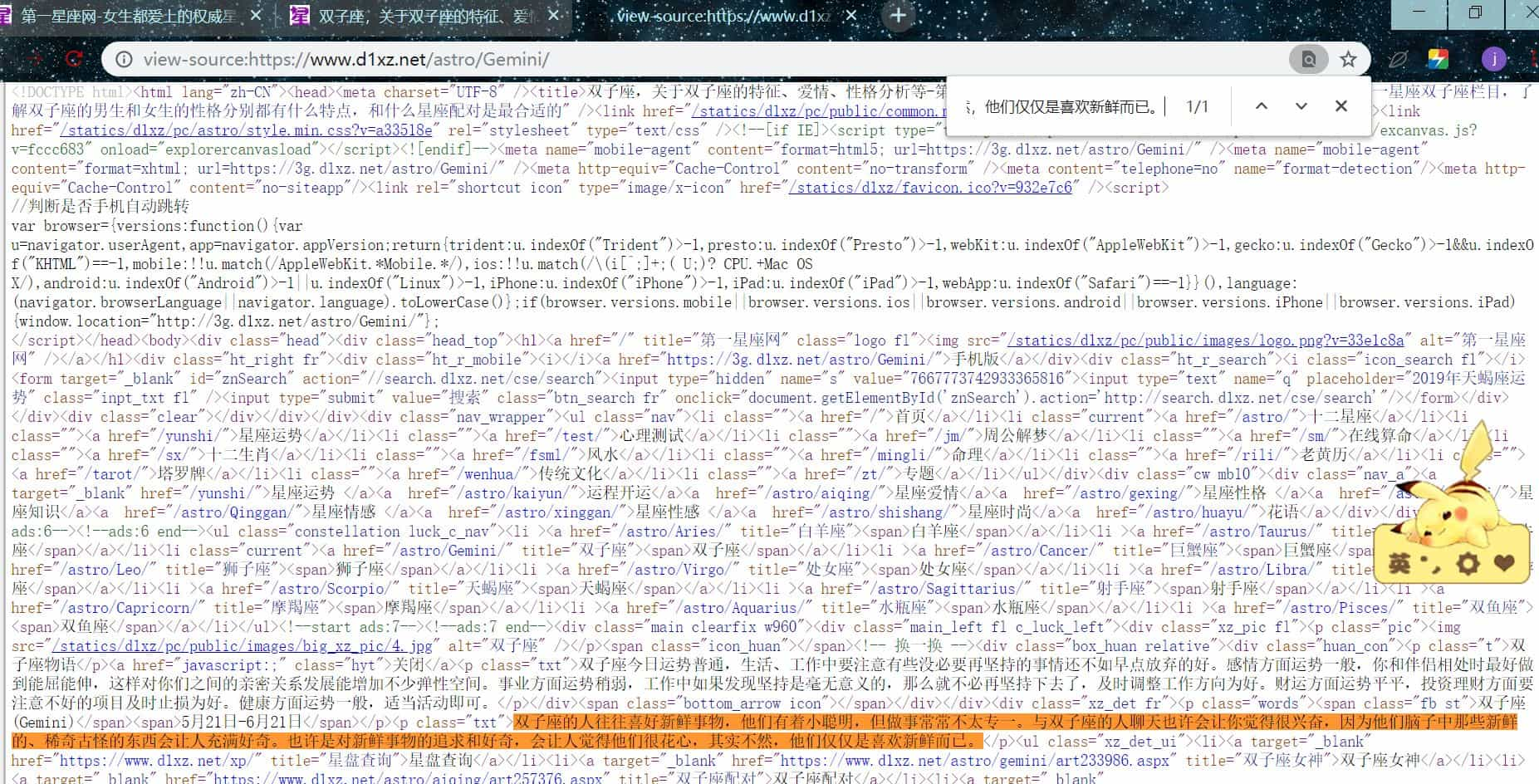
复制今日运势的描述,右键【查看源代码】,ctrl + f,把复制得粘贴进去,发现可以找到,说明网页是静态的
url 分析
我们对比一下几个星座的 url

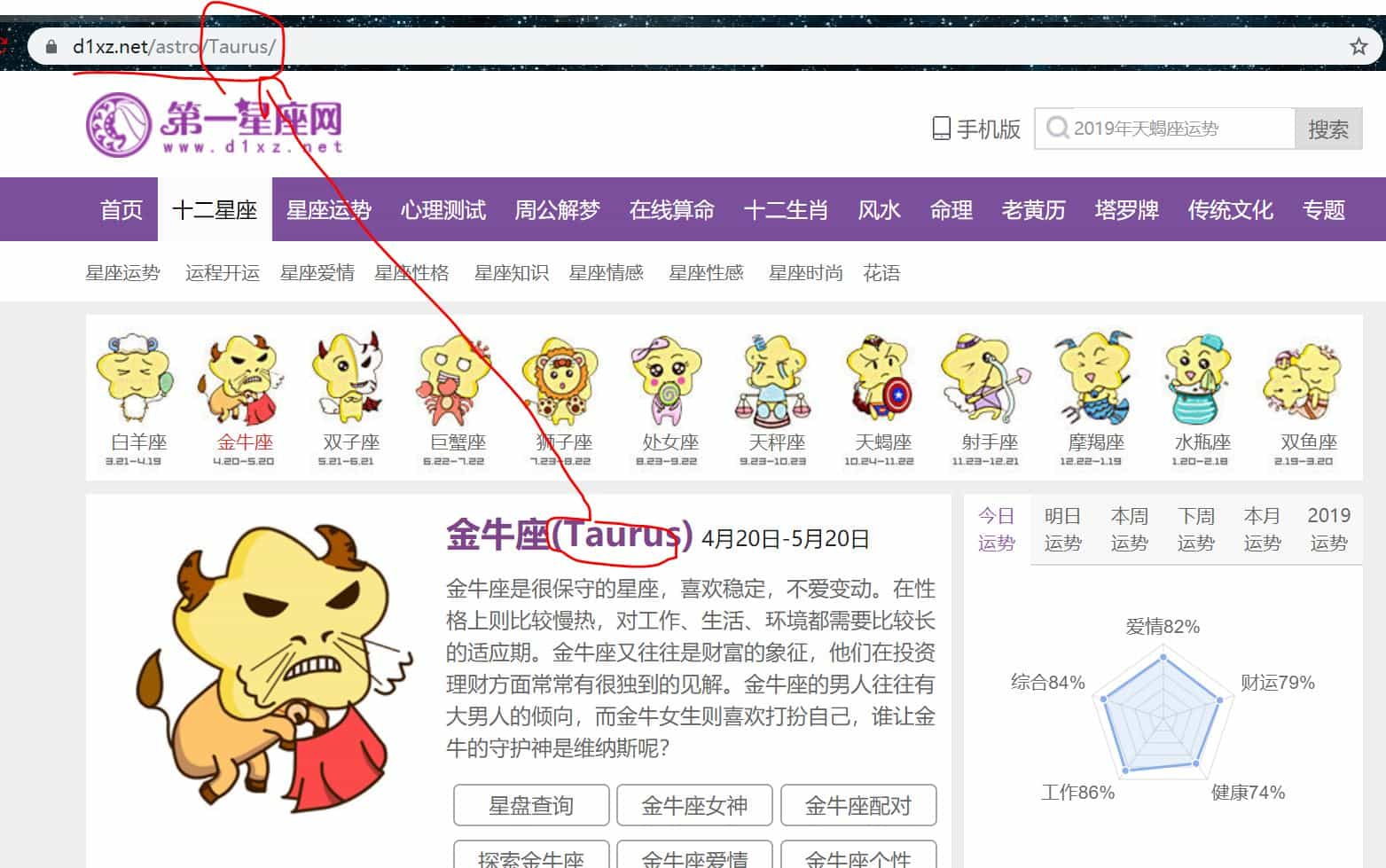

发现唯一变化的只有一个字段,这个字段就是星座的名字,英文的,由此我们可在在每次循环时构造对应 url 后再去访问
# 所有 12 星座的名称, 并构造 urls
constellation_name = ['Aries', 'Taurus', 'Gemini', 'Cancer', 'Leo',
'Virgo', 'Libra', 'Scorpio', 'Sagittarius',
'Capricorn', 'Aquarius', 'Pisces']
for _ in constellation_name:
url = 'https://www.d1xz.net/astro/{}/'.format(_)
请求 html
def get_html(url):
'''
请求 html
:param url:
:return: 成功返回 html,否则返回 None
'''
count = 0 # 用来计数
while True:
headers = {
'User-agent' : UserAgent().random
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response
else:
count += 1
if count == 3: # 超过 3 次请求失败则跳过
return
else:
continue
结构还是和前面教程的差不多,唯一变化的是,我们写的比前面更健壮了,我们可以请求 3 次,因为在某些时候可能网络或其他原因导致请求失败,所以我们设置可以请求 3 次,在 3 次都不行后,那跳过吧,因为爬虫是可以处理大部分请求的,只有少部分处理不方便,可以适当的跳过,没必要纠结这一两个
css 提取
选中今日运势的描述,右键【检查】
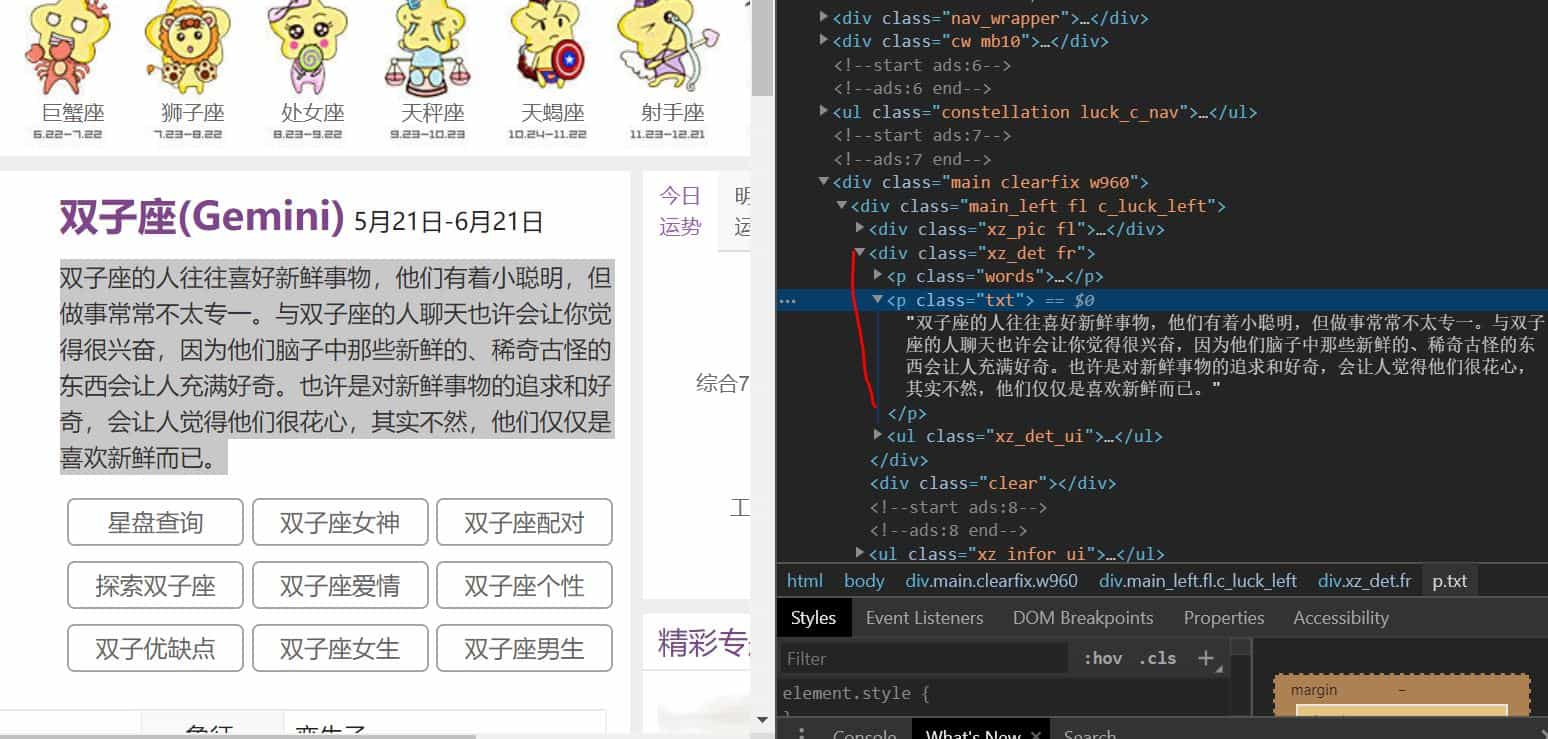
我们可以看到我们需要的文本在
<p class="txt"> .... </p>
它的父标签是
<div class="xz_det fr">
由此我们可以写出 css 表达式
html = etree.HTML(response.text)
luck = html.cssselect('.xz_det.fr > p.txt')[0].text
其中我们先需要使用 lxml 解析,再使用 cssselect 方法
.xz_det.fr:<div class="xz_det fr"> 它是父标签,所以写在第一个,“.” 代表 class,父标签的 class 值为 xz_det fr,所以写为 .xz_det.fr,可以不用管 div 了
‘>’:代表选取父标签的儿子标签,注意是儿子标签,在这里它的儿子标签就只有 p 标签,如果 p 标签下还有标签,那就叫父标签的孙子标签了
p.txt:在此例中,<p class="txt"> .... </p> 它是子标签,选择 p 标签 class 属性值为 txt 的标签
cssselect:返回列表,[0] 取出第一个结果
.text:提取出来后,我们得到的是标签,并不是文本,所以用它把文本从标签中提取出来
更多用法参考:
https://blog.csdn.net/qq_33472765/article/details/80843252
验证表达式
教大家一个方法,可以方便验证写的 css,xpath 表达式是否正确
f12 打开开发者工具,切换到如图所示:
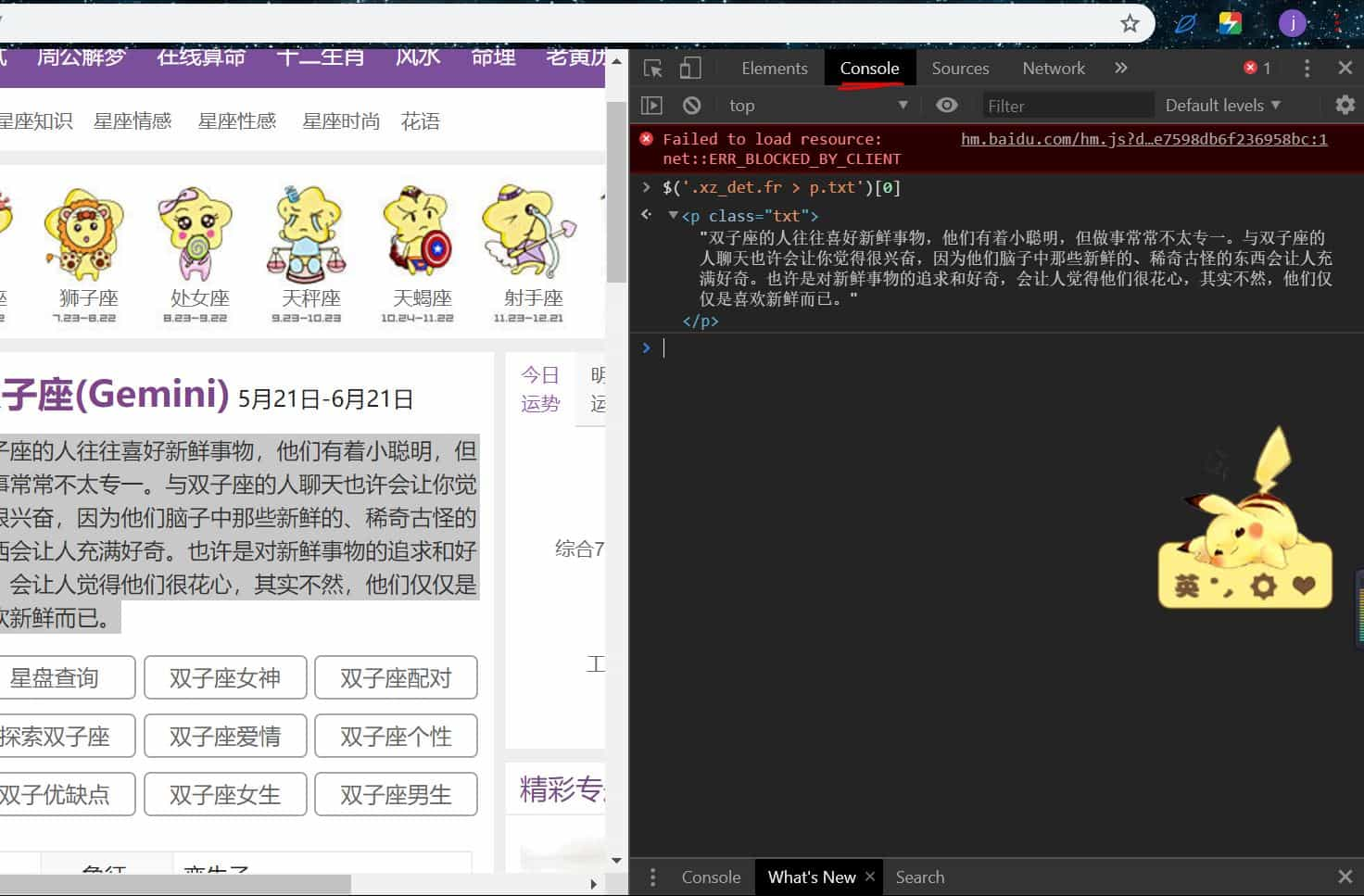
css 验证:输入 $() ,括号中写 css 表达式,如果正确那么就会有如图所示的显示提取结果,不正确那就没有结果
xpath 验证:输入 $x()
用此方法,可以方便的先验证表达式是否正确,再填入代码中
写入 txt
我们把爬取到的数据写入 txt,星座名+描述的形式
def write_txt(_,info):
'''
写入 txt 文件
:param _: 星座名
:param info: 星座运势
:return:
'''
with open('luck.txt','a+',encoding='utf-8') as f:
info = info.strip()
f.write(_ + '\n')
f.write(info + '\n\n')
END
到这里我们就结束了,下一篇我们采用 xpath 提取,完整代码如下:
import requests
import csv
import time
from lxml import etree
from fake_useragent import UserAgent
def get_html(url):
'''
请求 html
:param url:
:return: 成功返回 html,否则返回 None
'''
count = 0 # 用来计数
while True:
headers = {
'User-agent' : UserAgent().random
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response
else:
count += 1
if count == 3: # 超过 3 次请求失败则跳过
return
else:
continue
def get_infos(response):
'''
提取信息
:param response:
:return:
'''
html = etree.HTML(response.text)
luck = html.cssselect('.xz_det.fr > p.txt')[0].text
return luck
def write_txt(_,info):
'''
写入 txt 文件
:param _: 星座名
:param info: 星座运势
:return:
'''
with open('luck.txt','a+',encoding='utf-8') as f:
info = info.strip()
f.write(_ + '\n')
f.write(info + '\n\n')
if __name__ == '__main__':
# 所有 12 星座的名称, 并构造 urls
constellation_name = ['Aries', 'Taurus', 'Gemini', 'Cancer', 'Leo',
'Virgo', 'Libra', 'Scorpio', 'Sagittarius',
'Capricorn', 'Aquarius', 'Pisces']
for _ in constellation_name:
url = 'https://www.d1xz.net/astro/{}/'.format(_)
response = get_html(url)
if response == None:
continue
info = get_infos(response)
write_txt(_,info)
time.sleep(1)

