Start
我们做过爬虫是提取结构化数据的程序,这里我们选取了 2019 城市 GDP 排名信息作为例子,我们此次用正则提取其中的城市,GDP,人口,其他任何多余的都不要!
就一页网页,但要是这样的网页有多页,再来试试这个需求的话,网页中间,会看到很多多余的信息,直接复制粘贴,再去删减,在有很多页的情况下我们一定会感觉很麻烦,所以我们来学习一下正则的构造
http://caifuhao.eastmoney.com/news/20190201115604564011000
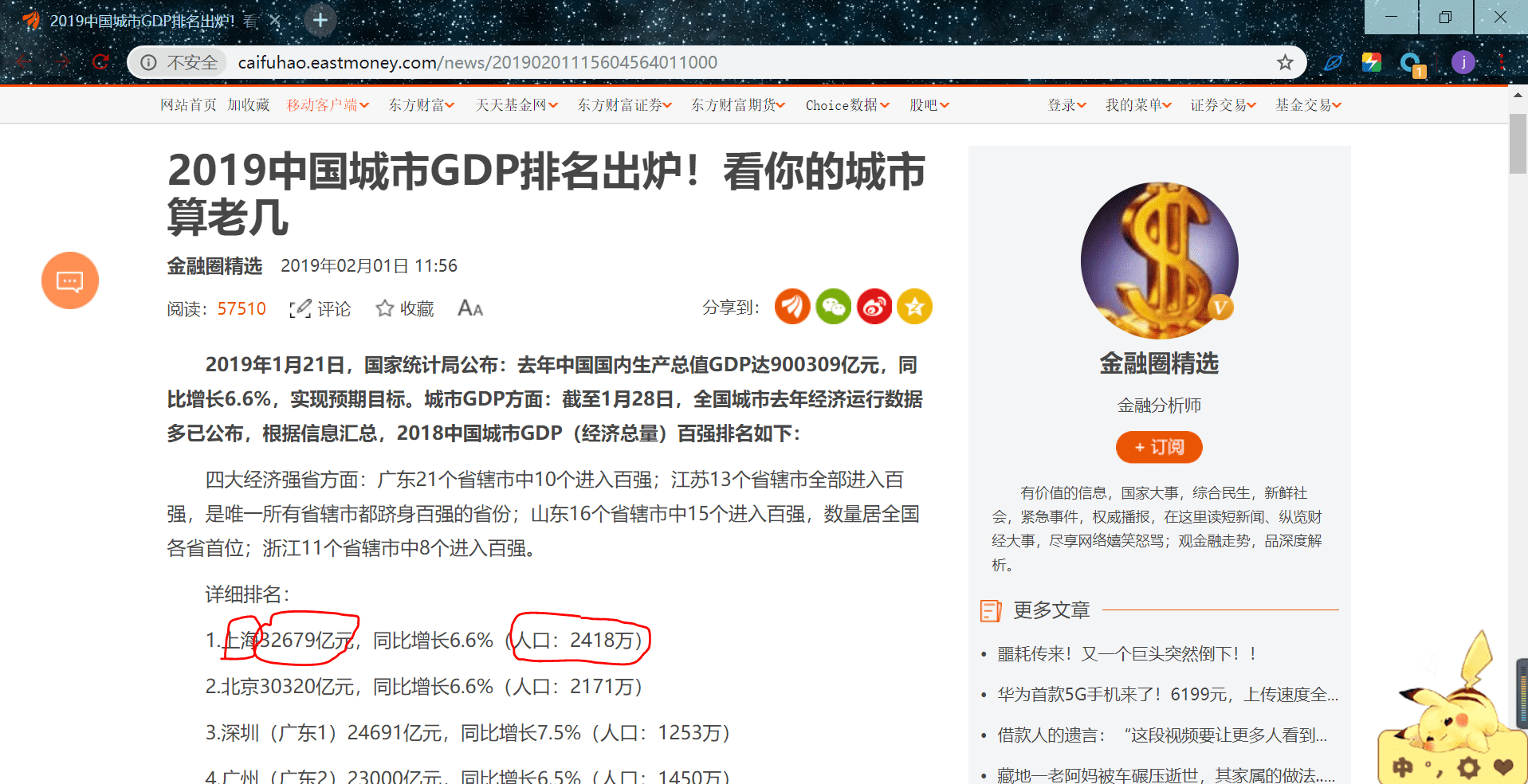
分析
随便复制一条我们的数据,然后右键查看网页源代码定位
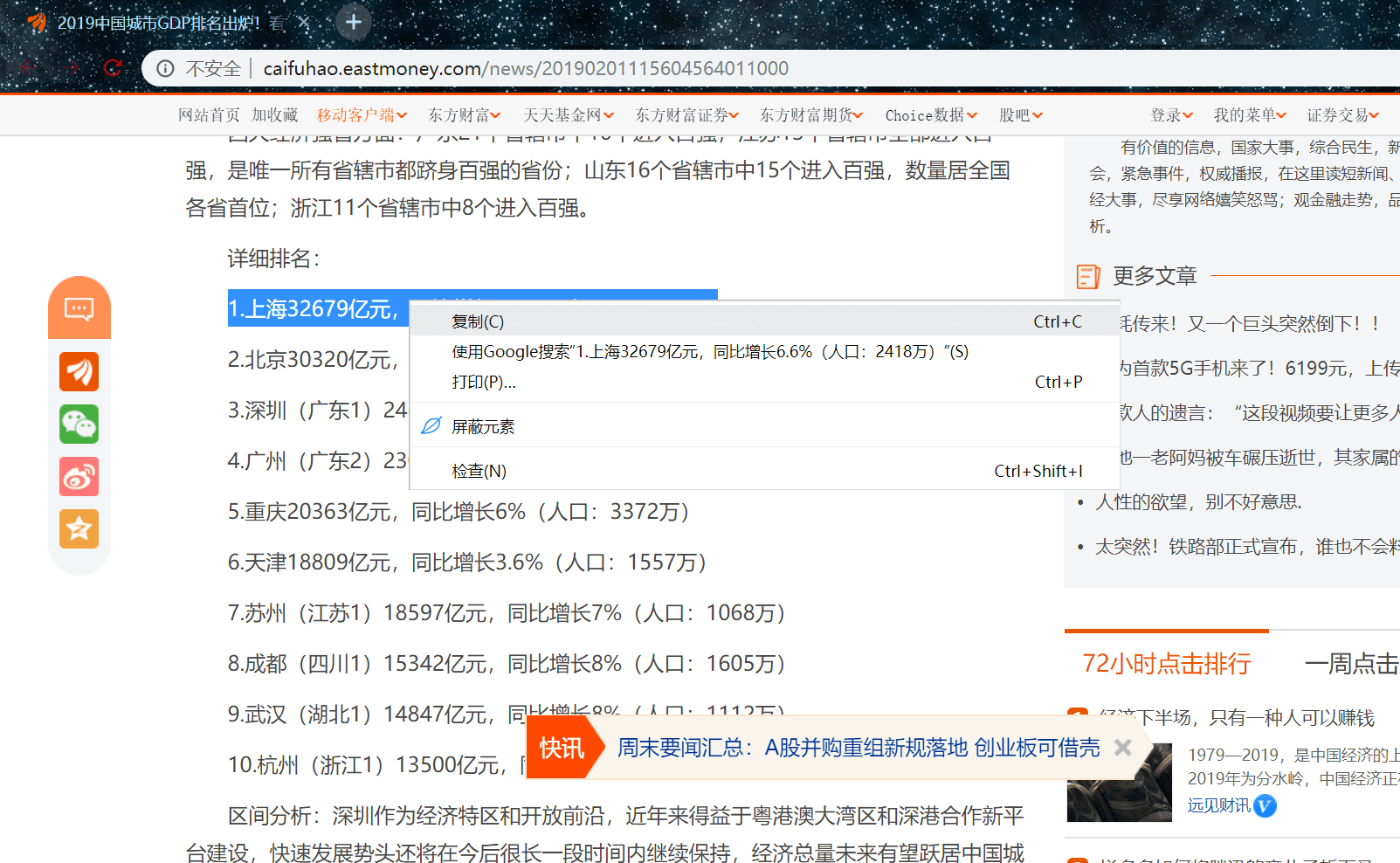

可以看到我们的数据都在
<p> ...... </p>
里面,但中间也有我们多余的信息,如下图:
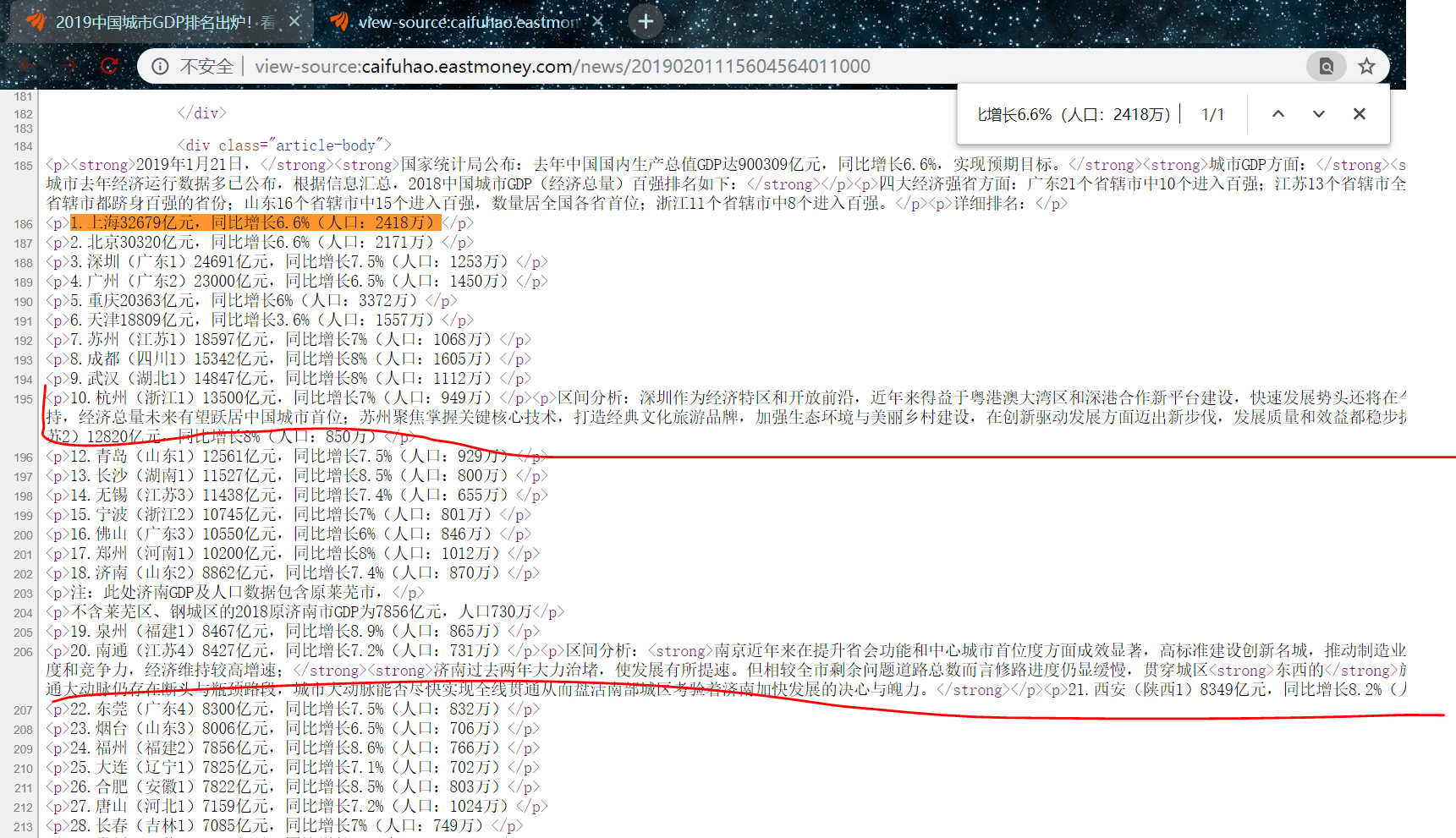
到这里,没有关系,因为我们提取下来后也是不符合我们需求的,所以把他们也一起匹配下来,就先不用剔除,我们构造正则表达式,来先把包含我们数据的标签匹配了
pat = '<p>(\d+.*?)</p>'
infos = re.findall(pat,html,re.S)
infos 是一个包含了每条
<p>...</p>
标签的列表,我在循环每一个标签再从中提取我们的数据,先来看人口和 GDP,观察,都是类似这样的结构:
2.北京30320亿元,同比增长6.6%(人口:2171万)
其中 “同比增长6.6%” 是多余的,我们不需要,所以提取城市,GDP,人口时,我们只能单独分别构造正则表达式
# 人数
pat1 = r'.*?(\d+)万)'
# GDP
pat2 = r'(\d+)亿元,'
# 城市
pat3 = r'\d+\.(.*?)\d+亿元,'
大家多对比一下上面的结构,就很容易明白,这些正则表达式
封装数据
try:
datas.append((city,GDP[0],people[0]))
except:
pass
我们为了打印方便,需要把对应的城市,GDP,人口封装在一起,使用了一个捕获异常,因为在爬虫提取时总会遇到一些不符合结果也返回了,但是少数,可以忽略
在封装前,我们通常都会把多余的字符剔除,或增加一些单位,例如城市:
# 城市
pat3 = r'\d+\.(.*?)\d+亿元,'
city = re.findall(pat3,info)
city = city[0].split('(')[0] + '市'
END
到这里,我们就完成了一次正则提取,还没明白正则表达式的,照着标签对比一下就知道为什么这样构造了,每个正则符号对应源网页中的什么字符
完整代码
import requests
import re
from fake_useragent import UserAgent
def get_html(url):
'''
下载 html
:param url:
:return:
'''
ua = UserAgent()
headers = {'User-Agent': ua.random}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return
def GDP_people_info(html):
'''
解析获得 GDP,人口的数据
:param response:
:return:
'''
pat = '<p>(\d+.*?)</p>'
infos = re.findall(pat,html,re.S)
# 处理提取的数据,以 [(城市,GDP,人数).....] 形式保存
datas = []
for info in infos:
# 人数
pat1 = r'.*?(\d+)万)'
people = re.findall(pat1,info)
# GDP
pat2 = r'(\d+)亿元,'
GDP = re.findall(pat2,info)
# 城市
pat3 = r'\d+\.(.*?)\d+亿元,'
city = re.findall(pat3,info)
city = city[0].split('(')[0] + '市'
try:
datas.append((city,GDP[0],people[0]))
except:
pass
return datas
if __name__ == '__main__':
'''
主接口
'''
url = 'http://caifuhao.eastmoney.com/news/20190201115604564011000'
html = get_html(url)
data = GDP_people_info(html)
print(data)
结果

