目标
https://pixabay.com/zh/images/search/?pagi=1
这是一个无版权图片的网站,我们可以随便用上面的图片,但每次都需要打开网页才能下载,并且是外国网站,加载有时会很慢,所以我们决定直接批量下载,保存下来,作为图库,下次有需要使用
分析
打开网页,选中一张图,右键,检查:
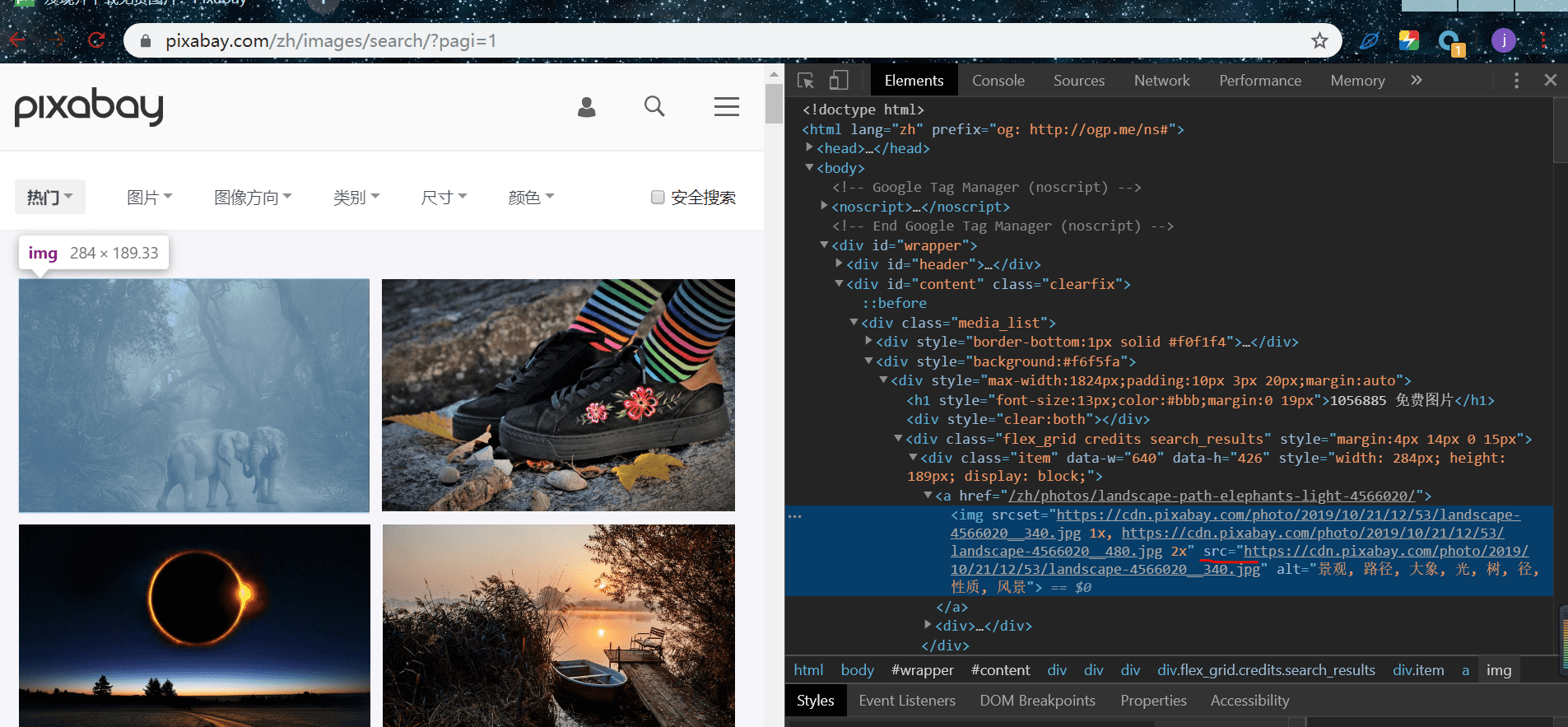
发现有一个 src 属性,对应的值是一个链接,我们打此开链接:
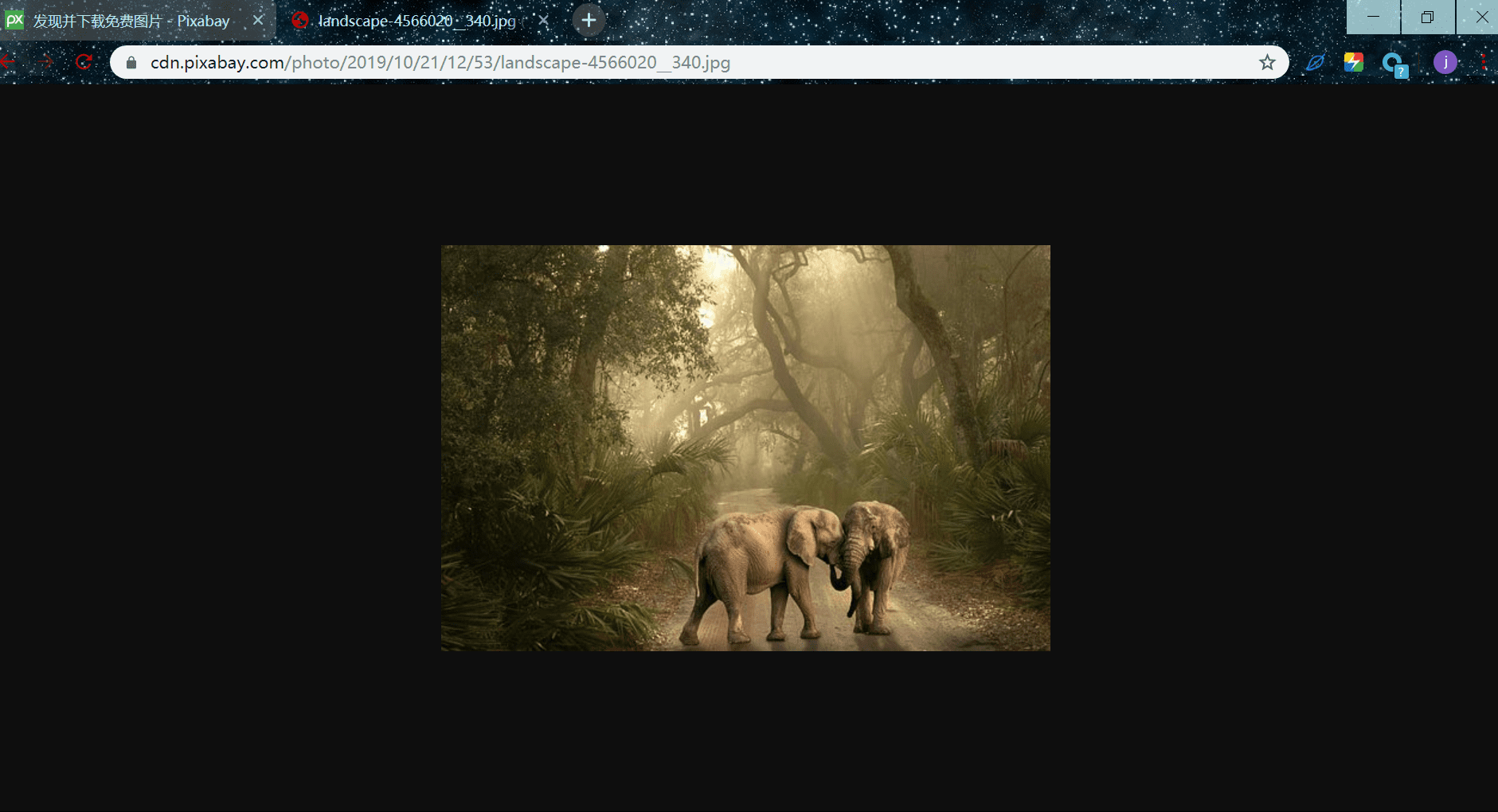
这就是我们需要请求下载图片的 url,我们复制此链接,在上一图中,右键,查看网页源码,查找此链接,从图中显示,此链接在里面,说明网页是静态的,我们可以从中提取出图片的 url:

我们再来翻几页,发现 url 变化的是 pagi,由此我们可以构造多页 url:

urls = ['https://pixabay.com/zh/images/search/?pagi={}'
.format(str(i)) for i in range(1,1001)]
请求网页
def get_html(url):
"""
请求 url 获得 html
:param url:
:return:
"""
headers = {
'User-agent' : UserAgent().random
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return None
提取图片的 url
urls = re.findall('<img srcset=".*?" src="(.*?)" alt=',
html,re.S)
保存图片
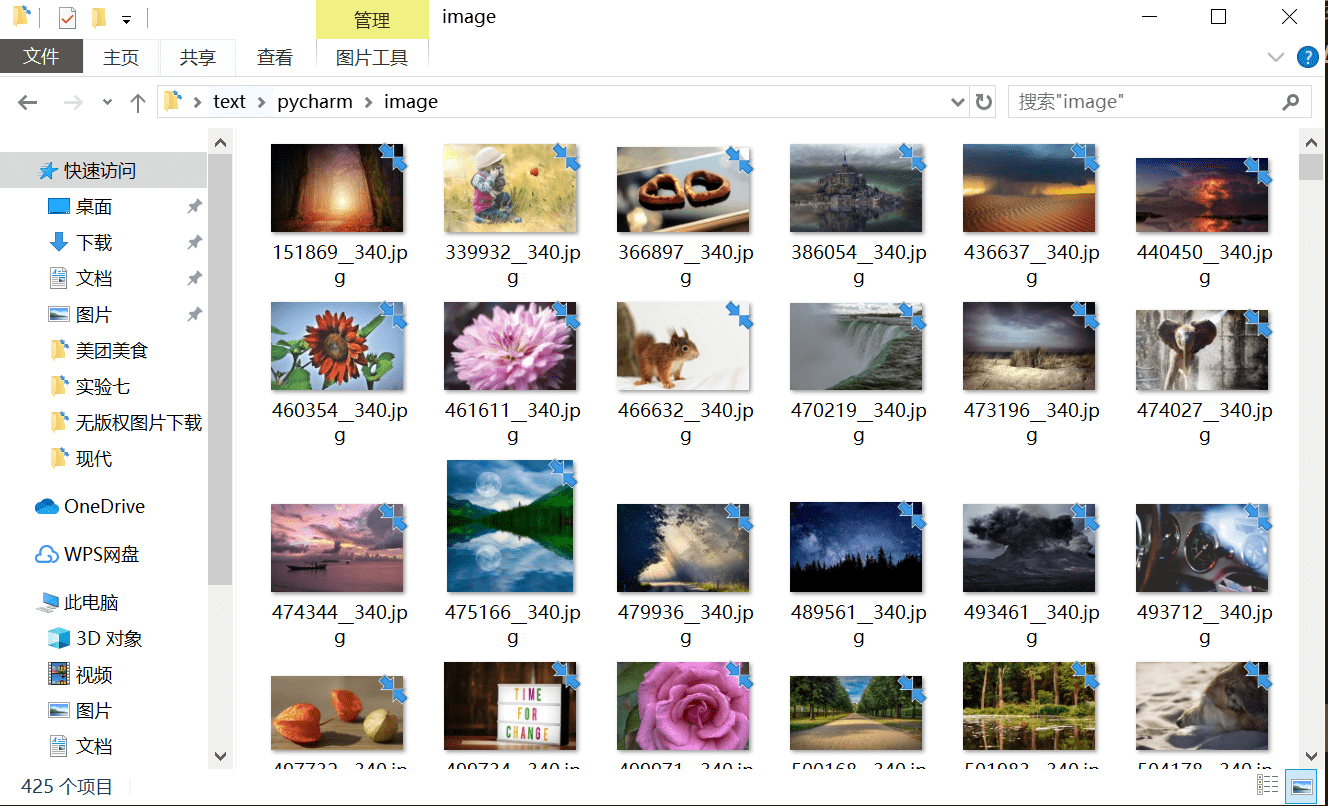
我们既然要下载图片,那就得保存起来,图片是以二进制形式存储的,写入时需要使用 wb 模式,我们可以单独创建一个文件夹用来保存图片:
import os
root = 'image/' # 创建文件夹的路径
path = root + url[-15:] # 取图片 url 的后 15 位字符作为图片名
if not os.path.exists(root): # 判断此路径是否存在,没有,则创建
os.mkdir(root)
if not os.path.exists(path): # 判断图片的路径是否存在,没有,下载图片
response = requests.get(url,headers={'User-agent' : UserAgent().random})
with open(path, 'wb') as f: # 以二进制写入
f.write(response.content) # response.content 返回请求的二进制格式
print('保存成功')
else:
print('图片存在')
END
我们到这里下载图片的流程就完成了
完整代码
import requests
import time
import re
import os
from fake_useragent import UserAgent
def get_html(url):
"""
请求 url 获得 html
:param url:
:return:
"""
headers = {
'User-agent' : UserAgent().random
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return None
def get_infos(html):
'''
提取图片 url
:param html:
:return:
'''
urls = re.findall('<img srcset=".*?" src="(.*?)" alt=',
html,re.S)
return urls
def download_img(img_urls):
'''
下载图片
:param img_urls:
:return:
'''
for url in img_urls:
#try:
root = 'image/'
path = root + url[-15:]
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
response = requests.get(url,headers={'User-agent' : UserAgent().random})
with open(path, 'wb') as f:
f.write(response.content)
print('保存成功')
else:
print('图片存在')
#except:
# pass
if __name__ == '__main__':
urls = ['https://pixabay.com/zh/images/search/?pagi={}'
.format(str(i)) for i in range(1,10570)]
for url in urls:
html = get_html(url)
if html == None:
continue
img_urls = get_infos(html)
download_img(img_urls)
time.sleep(1)
