全球平均温度与美国风暴数量相关性分析

20年6月22日 · 葛辰添 3597 人阅读
摘要:本程序的设计对象为全球地表平均温度的CSV文件与美国风暴数量的CSV文件。整理、分析这些文件中1950年至2015年66年间的数据内容,各自绘制成图表,将两张图表重叠显示,以及计算两种数据之间的相关性。
一、设计意图或研究目标
本程序的设计灵感来自于当前的地理现象“全球变暖”,有学者称全球变暖会造成极端天气数量的增加,本程序设计的目的就在于验证全球变暖与极端天气数量之间的相关关系。本程序最终要达成的目标是通过图表直观地展示两者的相关性,且通过计算两种数据间的皮尔逊相关值,判断两者间相关性的强弱。
二、数据文件
(1)全球平均气温文件
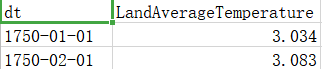 |
dt:气温数据的年份、月份、日期
LandAverageTemperature:地表平均气温(单位摄氏度)
(2)极端天气数量文件
 |
 |
 |
 |
BEGIN_DAY:该次极端天气开始的日期(具体几号)
BEGIN_YEARMONTH:该次极端天气开始年份、月份
BEGIN_TIME:该次极端天气开始的时间(具体到分钟)
STATE:极端天气发生的州
END_DATE_TIME:极端天气结束的日期时间
TOR_F_SCALE:龙卷风的等级
*原数据列数非常多,这里只展示用到的列
三、总体设计
(1)程序模块图
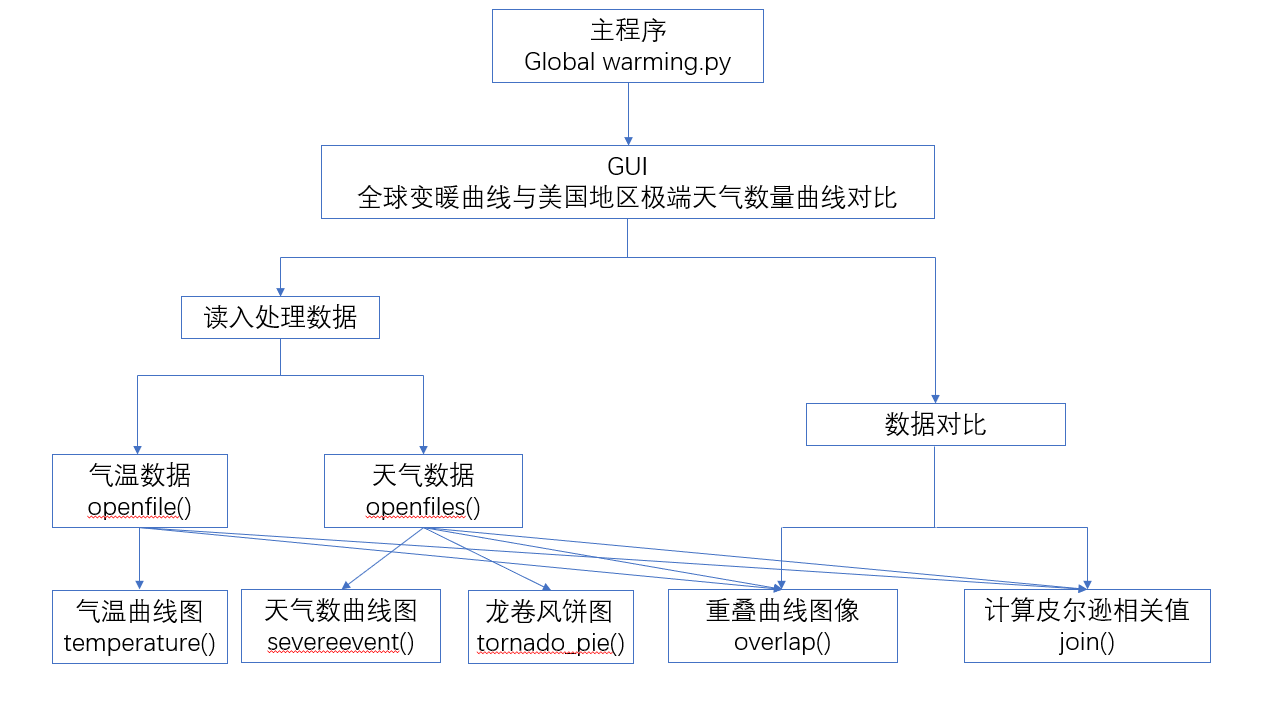 |
(2)GUI界面
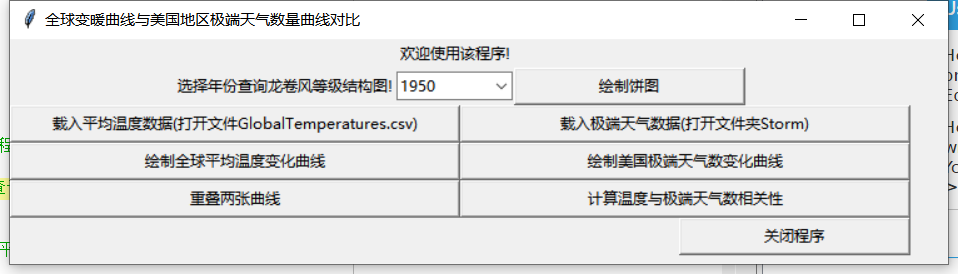 |
四、程序模块详细设计
(1)导入模块
(2)全局变量
x,y,x1,y1都是后续绘制的两张图表的x轴,y轴数据,test是后续处理极端天气数据生成的CSV文件读取的dataframe文件,plt.rcParams是为了图表title能够显示中文。
(3)打开并处理全球地表平均气温数据
将x,y全局变量引入,方便修改x,y值,为后续绘制图表及两种数据关联做好准备。因为全球平均温度只有一个CSV文件,因此采用了askopenfilename()读取文件。文件中的日期与地表平均气温是需要的数据,只把它们截取出来,用同列后一行的数据填补缺失数据,在当前数据修改,将日期的类型变为datetime,也统一了日期的书写格式。修改日期,我只需要年份。用groupby将这66年的数据分为以年划分的小部分,计算每年12个月的温度平均值。我们只要1950年以后的数据,将x轴数据变为年,y轴数据是计算出的每年平均气温。结束修改x,y全局变量的值。(处理绘制图片的时间较长,因此在读取数据后会在控制台显示“请稍等…”,结束时会提醒“平均温度数据载入完毕”)
(4)绘制平均气温曲线
将x,y全局变量引入,首先判断温度数据是否已经载入,如未载入,在GUI界面上提示先载入数据;如已载入,则绘制曲线。
(5)打开并处理美国每年风暴数据
将x1,y1全局变量引入,因为该数据集从网上拉下有66份CSV文件,所以考虑批量读取。此处使用了tkinter下filedialog.askdirectory()函数获取文件夹路径。输出路径使用直接路径,此处则为作品文件夹同目录下。调用os使得能从文件夹所在路径读取内部文件。对所有文件,采用for循环,一一读取。同样的,我们需要年份及发生灾害的数量。因为文件数量巨大,我们只读取其中能够用做删除冗余数据的列以及后续用来展示龙卷风数据的列(usecols=[0,1,2,8,19,31])。将冗余数据删除后,所剩数据行数即为该年份极端天气数量。将获取到的年份及算出的灾害数量重新变为dataframe格式concat到一起,以CSV格式输出。接着读取新生成的CSV文件,修改x1,y1的值,生成test。
(6)对美国每年风暴数量进行处理绘图
将全局变量x1,y1引入,同样先判断数据是否已经载入,未载入则提醒载入;已载入则绘制曲线。
(7)对龙卷风数据绘制饼图
引入test,x1,y1,后两者用来判断极端天气数据是否已经载入。Year获取下拉框选择的年份,设置饼图的x和label,再是设置饼图的大小等等,最后附上了藤田级数,对图中的数据进行解释。
(8)将两张图表重叠显示
为了更直观地看到两张图表的相似程度,采取重叠显示的方法。要确保我们的数据都是计算过的,CSV中的数据,先做一个判断。如果x,y,x1,y1其中一个长度依然是6,则说明有一套数据没有计算,在GUI界面上提示先计算。数据都准备好的情况下,开始设计图表。由于两个y轴数据上量级相差巨大,这里采用次坐标轴twinx(),最后显示图表。
(9)计算皮尔逊相关值
为了对数据本身进行比较,更精确地显示两种数据的相关性。这里采用皮尔逊相关值,我们直接导入sci.stats模块中的pearsonr算法,并对其进行分类显示在控制台。(后续附上了相关值对照表进行数据说明)
(10)关闭GUI界面及程序
关闭GUI界面,同时关闭程序。
(11)GUI界面设计及控件布置
先将界面分为上中下三个frame,最上层frame放置label,combobox和一个绘图button。中层两个数据的处理及绘图,最下层对比两数据,重叠绘图及计算相关性值。最后一层放置关闭button。
(11)GUI
将上述所有模块放入GUI()模块中。
(12)主程序
定义主程序。
(13)运行
五、数据可视化和结论
 |
 |
饼图共有66张,每年一张。每一张上是六个等级的龙卷风占当年所有龙卷风数的比例。以上图1950年为例,从最低的EF0级到最高的EF5级,占比例最高的是“一般龙卷风”,而“毁灭性龙卷风”并没有出现。前三级的龙卷风占到总数的90%左右,说明灾害水平总体还是偏低的。后面65年的数据也有这样的情况,所以大致说明,在灾害数量上升的背景下,高强度的灾害占总灾害数的比例并没上升,不必太担心超大自然灾害横行的情况。
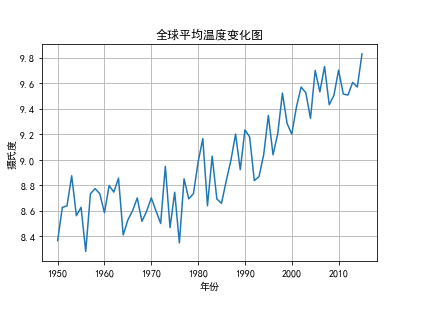 |
全球平均温度总体趋势是上升的,从1950年大约8.38摄氏度,到2015年大约9.81摄氏度。中间65年温度起起伏伏,比较曲折。
 |
美国本土极端天气数成上升趋势,从1950年200多起,发展到2015年40000多起。到1991年为止,数量上升比较平稳,随后陡然上升,到1996年左右有将近30000起。随后上升幅度变大,但变化也曲折不定。
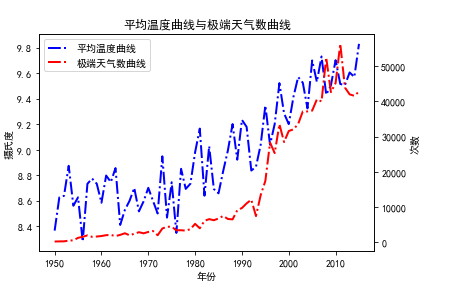 |
将两幅图像重叠在一起,能很直观地感受到两者同样的上升趋势。
 |
七、亮点
计算出皮尔逊相关值的大小是0.884,根据相关值的对应关系,判断出地表平均温度与极端天气数两者为强相关关系,即证明极端天气的发生与平均气温有关。
导入了os模块,使得能够通过文件夹路径读取其中所有CSV文件。
八、反思
绘制图像的两个函数实际上可以合并,即不采用全局变量,而改用传参。如此函数的可用性更强。总体数据量还是不够大,仅美国一地数据很难支撑起结论。且可视化维度不够,只采用了曲线图,还可以添加进各地极端天气数散点图。
九、更新日志
6月23日更新:
1.添加了龙卷风数据,可以绘制龙卷风饼图了。
2.对全球平均气温数据重新进行了冗余数据清洗(将同一次极端天气在同一州不同县的数据进行了清洗)。
3.重新排版了一些输出数据。
4.对原始数据中的一些名词进行了解释。
Python3Turtle
