饮食文化与预期寿命的关系

20年6月22日 · 朱雯美 2704 人阅读
一、主题
国际权威医学杂志《柳叶刀》发布了一份全球疾病负担(GBD 2017)研究系列报告。报告发现,影响人们健康的主要风险因素是健康食物摄入太少。所以根据目前可获得的数据,想要探究一些主要国家的饮食文化对预期寿命的影响。
二、摘要
饮食文化是一个抽象概念,难以定量,所以在这次报告中采用BMI和饮酒量两项指标来看饮食文化对预期寿命的影响,并提出相关建议以解决某些不当的饮食问题,帮助人们获得更好的身体健康,期望每个人都能长命百岁。
三、设计意图
希望能找到不同的饮食文化体系对预期寿命的影响,并探究中国饮食文化与日本(预期寿命第一位)饮食文化的差距,并提出相关饮食建议,优化人们饮食结构,获得一个更加健康的身体。
四、总体设计
1.程序模块图
 |
2.GUI界面
 |
五、程序模块详细设计
1.数据结构
Life Expectancy Data.csv是有关世界上所有国家的预期寿命表格,纵轴为不同的国家,横轴有时间(2000-2015),预期寿命,发展程度(发展中国家,发达国家),BMI,饮酒量,还有许多其他因素。所有名称均为英文。选取的数据仅为中日韩英美法德七国在2000-2015年间的数据。
2.技术准备
引入所需库:tkinter,numpy,pandas,pylab,scipy,seaborn,并利用plt.rcParams提高图片像素与分辨率
3.数据预处理
(1)读入数据文件Life Expectancy Data.csv,分组并提取所需要的国家的数据,将提出的dataframe英文数据改为中文
(2)实现数据分组求平均值并填充nan:用函数df.isna()查询nan的列,找出缺失的列然后用根据分组计算所求的平均值进行填充,方法是使用相同的index进行查找赋值
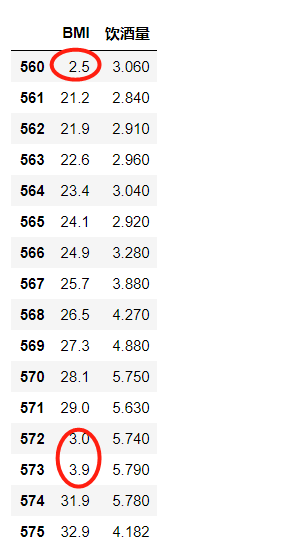
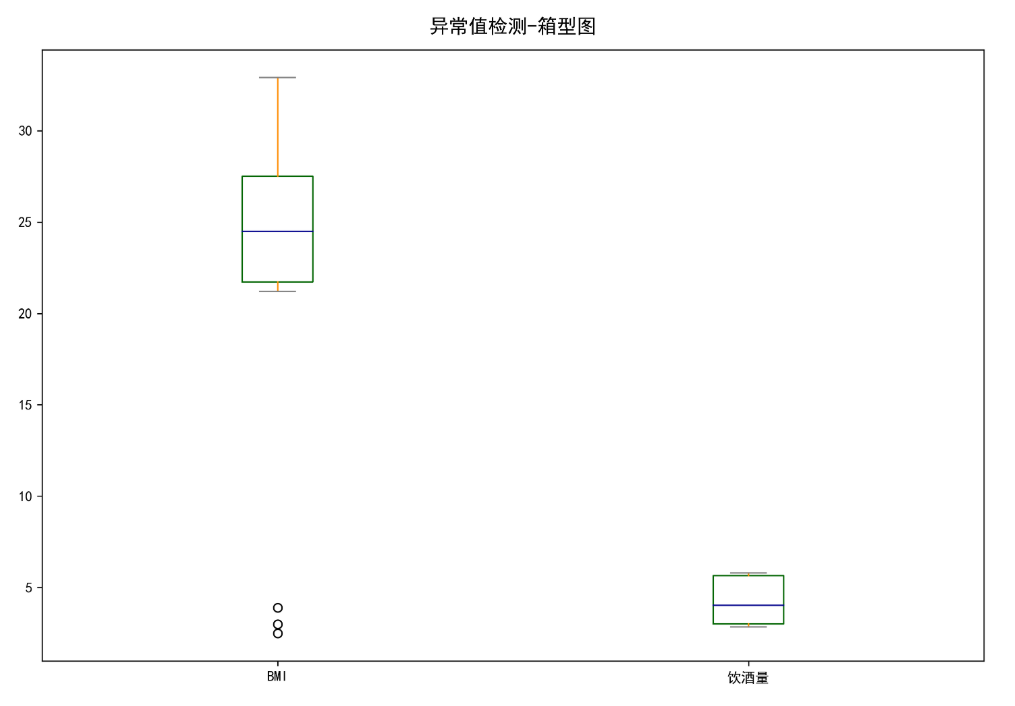
(3)数据异常化处理:采用方法为箱型图。首先利用箱型图的相关数据筛出异常值,并用nan进行替换,然后采用插值方法进行处理,利用fillna函数将中为数值填充进去,最后用.isna().sum()确认缺失值已处理
4.数据可视化处理
利用matplotlib首先画出对比柱形图和折线图的复合体,然后整理出所需数据,绘制排名的水平条形图,接着用sns.pairplot函数绘制出矩阵散点图,最后将数据进行归一化处理,直观地展现二者关系的折线图(BMI与预期寿命,饮酒量与预期寿命),供读者阅读
5.GUI界面设计
主要使用Label,Button,Combobox以及相关属性,利用grid函数确定位置
六、数据可视化和结论
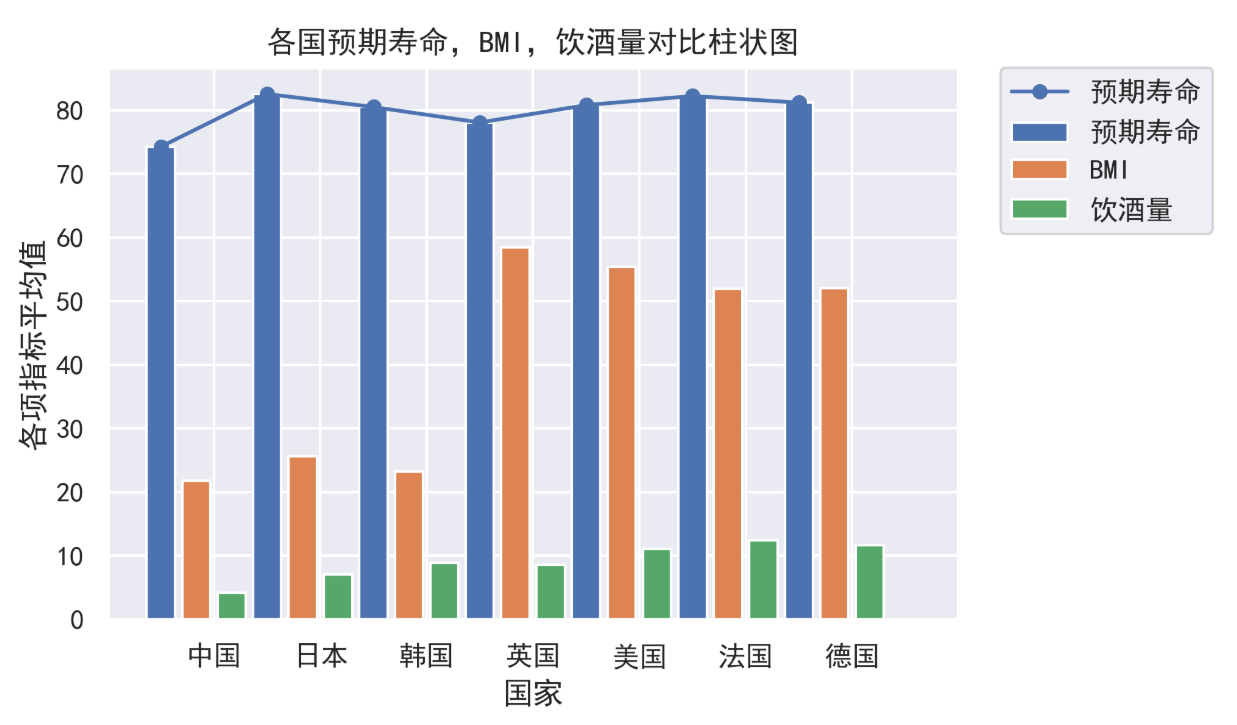 |
结论1:可以明显看出左边三个国家BMI值和饮酒量较为接近,右边四个国家也有相对的一致性,可以将其分为两个饮食文化体系:东亚饮食文化体系和欧美饮食文化体系。饮酒量方面二者相差不大,但BMI值欧美系国家几乎是东亚国家的二倍,说明欧美国家肥胖人数居多,与其高糖高油的饮食习惯有一定的关系。即便如此,中国的预期寿命仍然在其中为最低值,考虑此数据为2000-2015年间的数据,认为原因应该是,当时中国处于发展中国家上升阶段,人民温饱水平仍然难以达到,所以低BMI值并非代表健康的饮食习惯,而是处于偏瘦或接近正常的阶段,类似于营养不良,所以预期寿命较低。
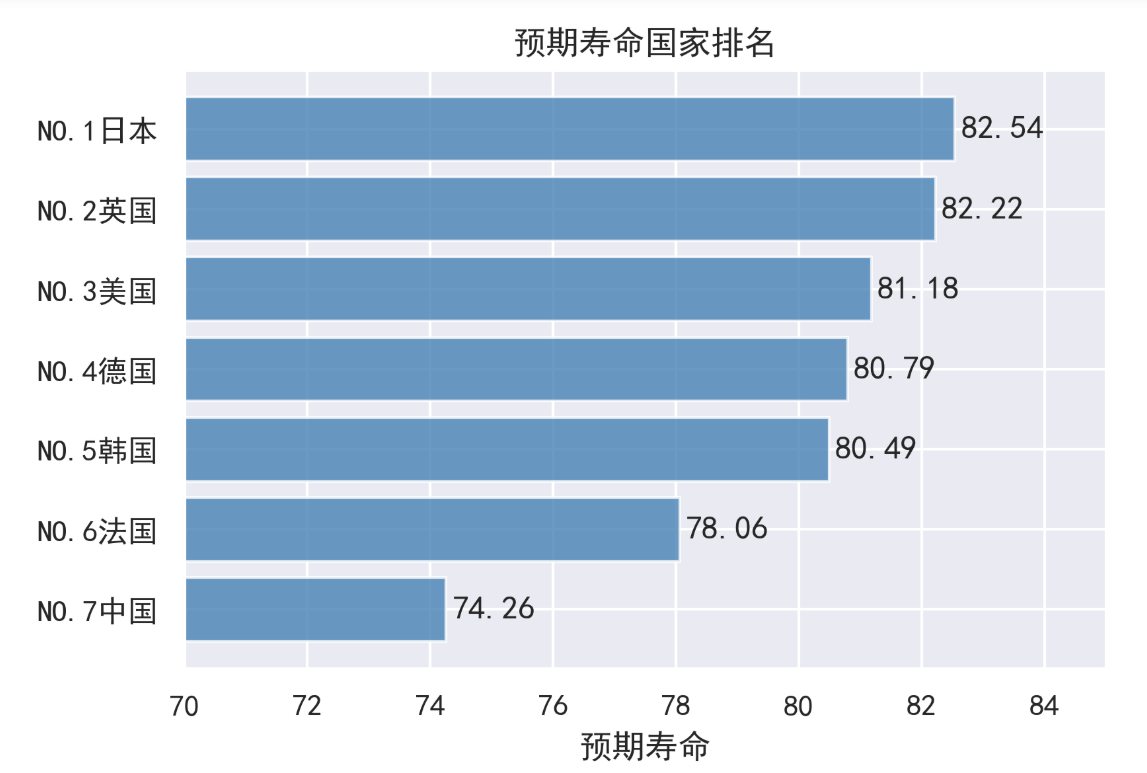 |
结论2:图表显示,日本的预期寿命位于这些国家行列中的第一位。英国医学杂志《柳叶刀》曾提到过,一般认为,合理的饮食是日本人长寿的主要原因之一,日本人喜欢吃鱼和豆类。豆制品则被认为能有效防止动脉硬化。研究认为,鱼类含有丰富的不饱和脂肪酸DHA和EPA,EPA可使血液不易形成血栓,具有预防中风及心肌梗塞的效果。所以,良好的饮食结构的确有利于延年益寿,在这个方面我们还需要多多借鉴日本的有益饮食结构。
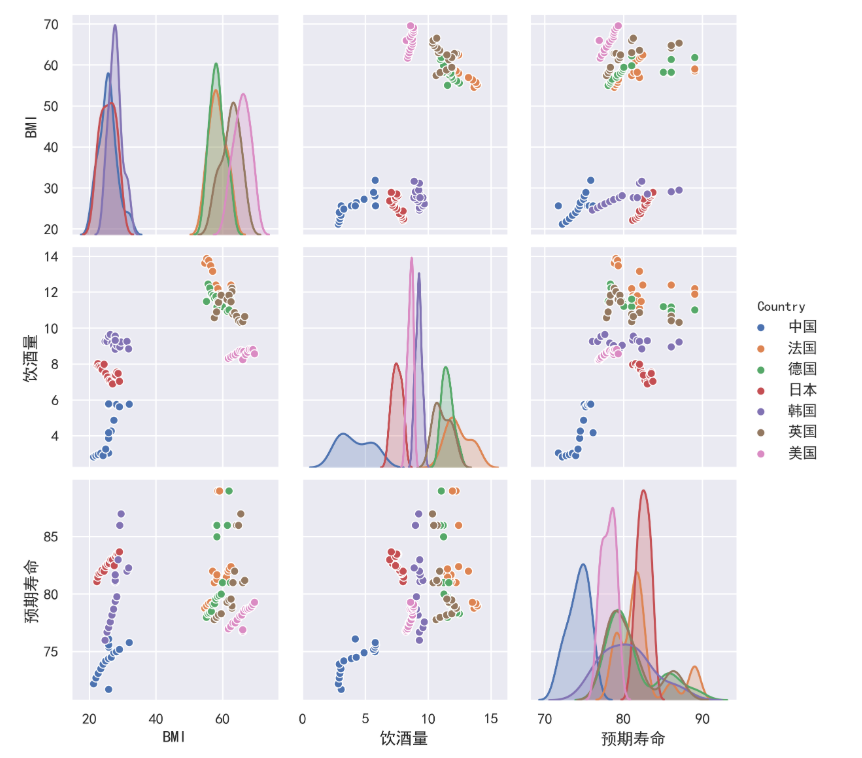 |
结论3:根据左下角第一幅图,可以明显看出中日韩为一类,英美法德为一类,二者BMI值相差较多,也可以印证结论1,我国的BMI值最大水平仍然没有达到欧美国家的最低值。虽然与日本类似,但不可忽略的是日本为发达国家,而我国为发展中国家,二者BMI值低的原因不同。在饮酒量方面,可以看自下往上第一行中间一列,这是中国独自一类,其他国家为一类。可以看到,中国十三亿人的平均饮酒量远低于其他国家。调查显示,适度饮酒可以降低心血管疾病,但切忌不宜过量。
 |
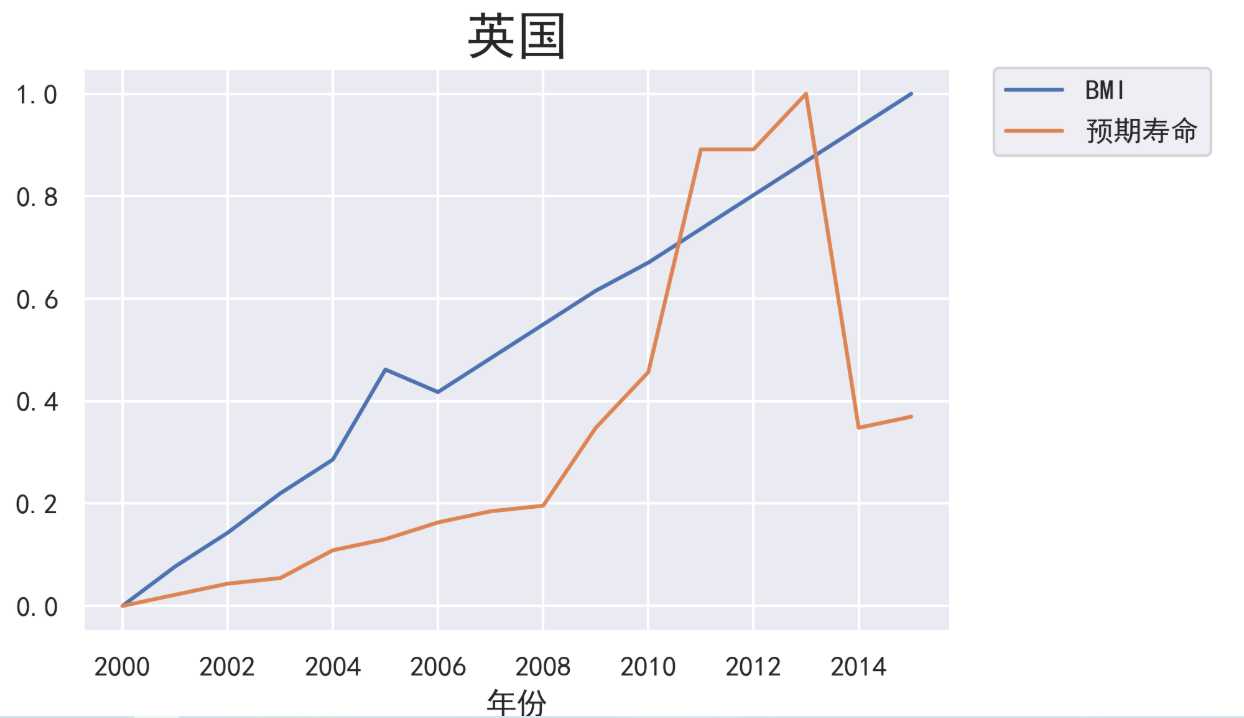 |
结论4:中国的预期寿命随BMI值的增长而增长,而英国先随之增长,后反而下降。得出的建议是:采取中庸思想。中国BMI值增长是趋近于BMI值的最佳位置点,从侧面也可以看出我国生活水平的上升,而英国初始阶段已在最佳位置点附近,超过而犹不及,所以饮食不要过多也不要过少,秉持中庸思想为最佳。
七、亮点
 |
|
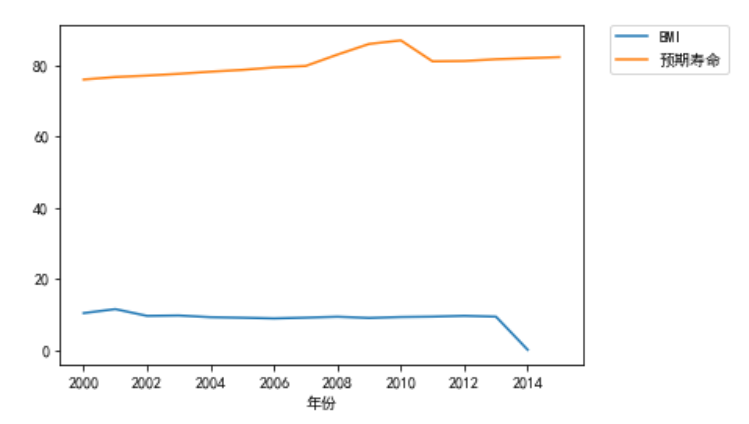
此为第二点的图(由于在中间插入不了,只能出此下策)
 |
 |
 |
此为第四点的图
1. 采用对比柱形图和折线图来比较两种饮食文化的差别,采用水平条形图展示国家间预期寿命的排名,采用矩阵散点图来看BMI,饮酒量,预期寿命的相关联系。
2. 由于预期寿命与BMI,饮酒量数据值相差较大,所以采用数据归一法让二者同时存在于0-1内,更加方便对比两者之间的走势,然后用折线图进行实现。上图为前后对比。
3. 找出nan缺失值,然后分组,并计算分组后的平均值,利用index相等,逐列用平均值填充。
4. 采用箱型图进行数据异常自检测。首先计算箱型图所需数据,放入列表并用pd.concat进行合并。然后处理异常值,将正常的数据以数据框的形式筛选出来,返回一个已用nan替换掉异常值的Dataframe,然后用fillna函数将中位数值填充到nan中,并用.isna().sum().sum()检查空值是否已处理。
5. 新采用的小点,使用起来很方便,推广给大家:
(1)用plt.rcParams['figure.dpi], plt.rcParams['savefig.dpi]可以提高图片的分辨率和像素,使图片更加清晰。
(2)Button中有一个叫overrelief的属性,可以设置为overrelief='sunken‘,这样Button就可以呈现3D效果,鼠标移到Button内部和点击都有特效。
(3)如果在jupyter notebook中误删代码,不要关闭界面,输入history就可以出现之前的代码(血淋淋的教训)。
八、反思
- 样本信息有限,难以获取进一步的数据,结论需要其他信息进行弥补,否则过于单一;数据样本有限,难以获得期待的结论。
- 前期数据处理耗时较多,后期图形展示没有太多亮点,只是多样化地使用图形表达,而数据处理的亮点很难展现出来,陷入两难境地。
Python3Turtle
