2025 Python 计算生态十一月推荐榜 第93期

25年11月10日 · Python123 3252 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
在多模态与文档智能全面走向生产的2025年,OCR 已不再是图片转文字的单点技术,而是贯穿采集、解析、结构化、检索与合规留痕的全链路能力。从票据、合同、发票,到研发资料、学术论文、表格与公式,甚至屏幕录制与扫描件,稳定高效的识别与版面理解直接决定数据工程与知识工程的上限。对 Python 开发者而言,工程实践要格外关注。大尺寸页面的切块与并行、检测和识别的流水线调度、版面、表格结构恢复、可恢复上传与分布式缓存、GPU、CPU、ONNX 部署、量化与蒸馏、以及合规审计与隐私数据最小化处理等。
在2025年11月 AI 原生文档处理的趋势下,开源 OCR 模型与生态快速迭代,端到端识别模型不断提升鲁棒性,多语言、跨域适配更完善,PDF长页图推理更高效,结构化输出成为一等产物。下面推荐 10 项 Python 方向的 OCR 模型与工具,首推 DeepSeek-OCR,兼顾通用性、工程可落地性与社区活跃度,覆盖从研究到生产的常见需求。
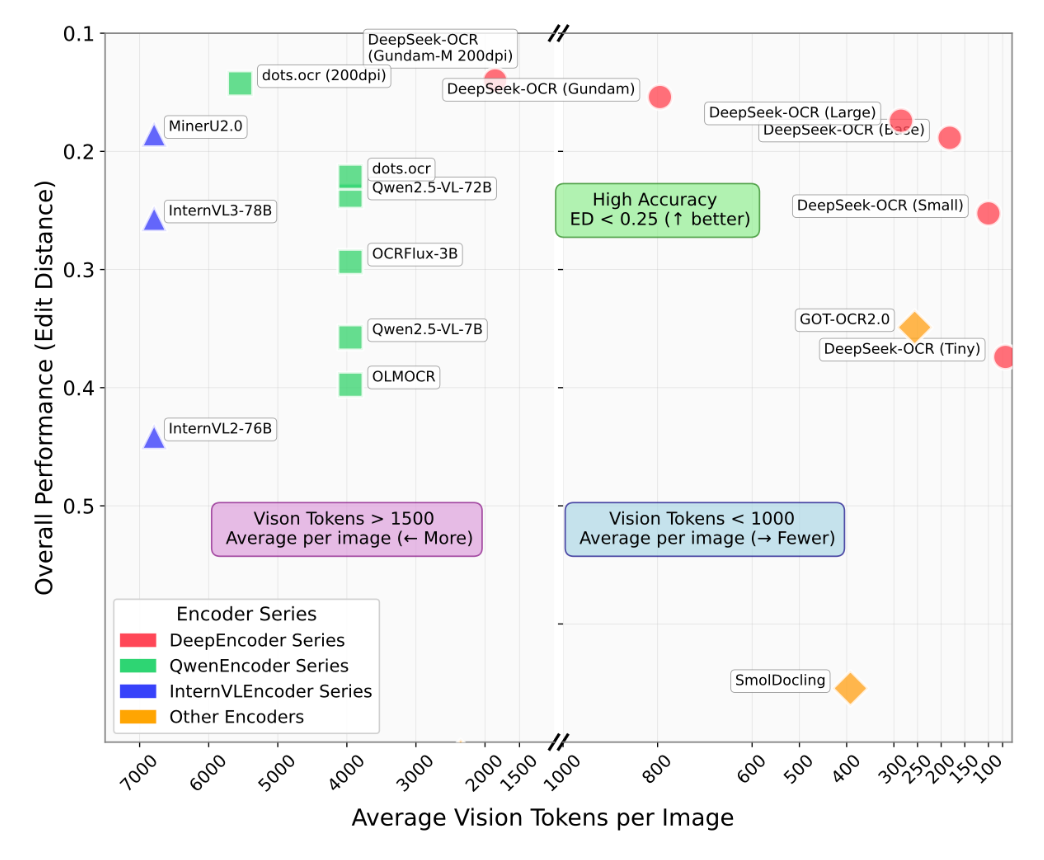
DeepSeek-OCR
DeepSeek-OCR是deepseek-ai 出品的开源 OCR 模型与工具链,主打高精度与工程友好,支持多语言与复杂版面识别,提供检测-识别一体化流水线与批处理接口,适配 GPU、CPU 推理并支持导出部署。适合票据、合同、扫描文档与技术论文等场景的端到端抽取与结构化还原。
https://github.com/deepseek-ai/DeepSeek-OCR
PaddleOCR
PaddleOCR 工业级开源 OCR 套件,覆盖文本检测、识别、版面与表格结构恢复,多语言模型齐全,提供轻量化与服务器推理方案,Python API 完备,便于快速落地到批处理与在线服务。
https://github.com/PaddlePaddle/PaddleOCR
mmocr
MMOCR OpenMMLab 文档视觉与场景文本工具箱,模块化地组合检测/识别/版面模型,训练与评测规范化,便于研究与自定义数据集上的迁移学习与实验复现。
https://github.com/open-mmlab/mmocr
docTR
docTR 基于 PyTorch、TensorFlow 的文档文本检测与识别库,API 简洁,内置多种预训练模型,易与常见的 PDF/图像处理流水线集成,适合工程快速集成。
https://github.com/mindee/doctr
EasyOCR
EasyOCR 即拿即用的轻量级 OCR 库,支持 80+ 语言,安装与调用门槛低,适合原型验证、小规模批处理与对时延要求不高的任务。
https://github.com/JaidedAI/EasyOCR
pytesseract
pytesseract Tesseract 的 Python 绑定,传统 OCR 生态的坚实基座。依托系统级 Tesseract,适合离线、资源受限与合规偏好的场景;对印刷体文档具备良好稳定性。
https://pypi.org/project/pytesseract/
TrOCR
TrOCR 基于 Transformer 的端到端识别思路,适用于印刷体、手写等多场景,可通过 Hugging Face Transformers 直接推理或微调,便于与现有 NLP、多模态管线融合。
https://huggingface.co/microsoft/trocr-base-printed
LayoutParser
LayoutParser 面向文档视觉的版面解析工具箱,提供版面/区域检测与可视化,常与 OCR 识别模块搭配使用以完成“检测→切块→识别→重组”的结构化流水线。
https://github.com/Layout-Parser/layout-parser
RapidOCR
RapidOCR 面向工程实战的轻量 OCR 方案,启动快、依赖少,适合在边缘或容器环境中快速部署通用识别能力。
https://github.com/RapidAI/RapidOCR
OCRmyPDF
OCRmyPDF 将 PDF 加入可搜索文字层的实用工具,常与 Tesseract其他识别模型组合,实现归档件与扫描文档的批量可检索化处理。
Python3Turtle
