2025 Python 计算生态二月推荐榜 第84期

25年2月10日 · Python123 2948 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
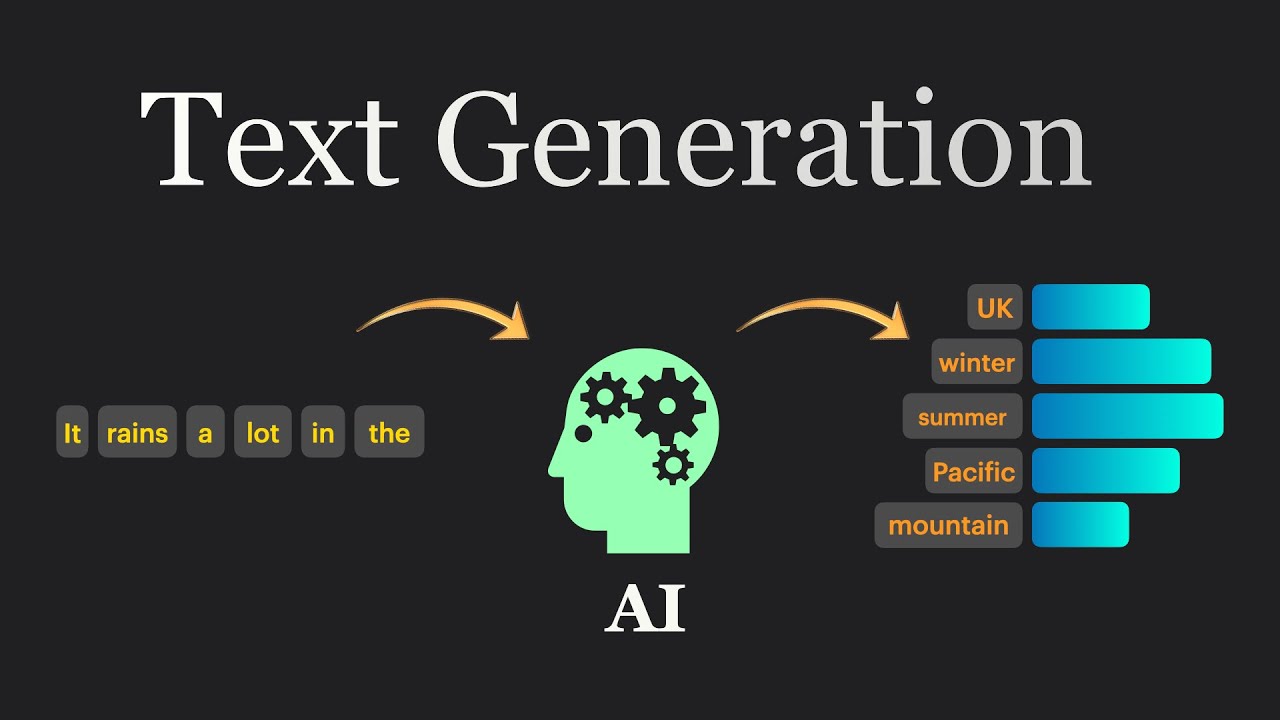
文本生成(Text Generation)是自然语言处理(NLP)中的一个任务,指的是使用计算机算法生成自然语言文本。这个过程可以涉及从简单的句子生成到复杂的段落或文章撰写。文本生成的工作原理基于机器学习模型,尤其是自然语言处理(NLP)中的循环神经网络(RNN)、长短时记忆网络(LSTM)和Transformer模型。这些模型通过分析大量的文本数据,学习语言的统计规律和结构,从而理解词汇、句子和整个文档的组织方式。在训练过程中,模型学习如何根据给定的上下文预测下一个最可能的词或字符,这种能力使得模型能够生成连贯且语法正确的文本。
在2025年2月,随着DeepSeek-R1系列模型的发布,文本生成迎来新的技术突破。为此,我们特别推荐了10款优秀的Python计算生态工具和框架,以帮助开发者全面理解和掌握自然语言处理中的文本生成技术。
DeepSeek-R1
DeepSeek-R1是幻方量化旗下AI公司深度求索(DeepSeek)研发的推理模型,采用强化学习进行后训练,擅长数学、代码和自然语言推理等复杂任务。该模型在数学竞赛问题上取得突破性的准确率,展示了专家级的编程能力。
https://huggingface.co/deepseek-ai/DeepSeek-R1
DeepSeek-V3
DeepSeek-V3 是一款强大的专家混合(MoE)语言模型,总参数达 671B,每个词元激活 37B 参数。它采用多头潜在注意力(MLA)和 DeepSeekMoE 架构,无辅助损失的负载均衡策略及多词元预测训练目标,在 14.8 万亿词元上预训练,并经监督微调与强化学习阶段。此模型具有强大的多模态理解能力,适用于不同应用场景,并具有高效的资源利用效率。
https://huggingface.co/deepseek-ai/DeepSeek-V3
Qwen2.5
Qwen2.5是阿里云发布的新一代开源模型,包括大语言模型、多模态模型、数学模型和代码模型。全系列模型在18T tokens数据上进行预训练,相比Qwen2,整体性能提升18%以上,拥有更多的知识、更强的编程和数学能力。
https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9e
Qwen2.5-Math
Qwen2.5-Math 是 Qwen2-Math 的升级版本,包括基础模型 Qwen2.5-Math-1.5B/7B/72B,指令微调模型Qwen2.5-Math-1.5B/7B/72B-Instruct 和数学奖励模型 Qwen2.5-Math-RM-72B。相较于 Qwen2-Math 只支持使用思维链(CoT)解答英文数学题目,Qwen2.5 系列扩展为同时支持使用思维链和工具集成推理(TIR) 解决中英双语的数学题。Qwen2.5-Math 系列相比上一代 Qwen2.5-Math 在中文和英文的数学解题能力上均实现了显著提升。
https://huggingface.co/collections/Qwen/qwen25-math-66eaa240a1b7d5ee65f1da3e
Llama 3.2
Llama 3.2 是 Meta 发布的一个多语言大型语言模型,具有 11B 和 90B 的视觉语言模型。相较于 Llama 2,Llama 3.2 的主要改进在于词表和 GQA(Grouped Query Attention)。
https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf
Phi-3
Microsoft 推出 Phi-3,这是 Microsoft 开发的一系列开放式 AI 模型。 Phi-3 模型是一个功能强大、成本效益高的小语言模型 (SLM),在各种语言、推理、编码和数学基准测试中,在同级别参数模型中性能表现优秀。 为开发者构建生成式人工智能应用程序时提供了更多实用的选择。
https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3
GLM-4
GLM-4是智谱AI于2024年1月推出的新一代基座大模型,具有与GPT-4相近的性能,强大的多模态能力以及All Tools和个性化智能体功能。GLM-4整体性能相比GLM3全面提升60%,逼近GPT-4;支持更长上下文;更强的多模态;支持更快推理速度,更多并发,大大降低推理成本;同时GLM-4增强了智能体能力。
https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7
BERT
基于变换器的双向编码器表示技术 ( Bidirectional Encoder Representations from Transformers, BERT)是用于 自然语言处理 (NLP)的预训练技术,由 Google 提出。2018年,雅各布·德夫林和同事创建并发布了BERT。
https://huggingface.co/google-bert
ModernBERT
ModernBERT 是一个全新的模型系列,在 速度 和 准确性 两个维度上全面超越了 BERT 及其后继模型。 这个新模型整合了近年来大语言模型(LLMs)研究中的数十项技术进展,并将这些创新应用到 BERT 风格的模型中,包括对架构和训练过程的全面优化。 我们预计 ModernBERT 将成为目前广泛应用编码器模型领域的新标准,特别是在检索增强生成(RAG)管道和推荐系统等应用场景中。
https://huggingface.co/collections/answerdotai/modernbert-67627ad707a4acbf33c41deb
gpt2
GPT-2是 OpenAI 在2019 年推出的第二代生成式预训练模型。 GPT-2与GPT-1架构相同,但是使用了更大的数据集 WebText,大约有 40 GB 的文本数据、800 万个文档,并为模型添加了更多参数(达到15 亿个参数),来提高模型的准确性,可以说是加强版或臃肿版的 GPT-1。
Python3Turtle
