2024 Python 计算生态六月推荐榜 第76期

24年6月10日 · Python123 18523 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
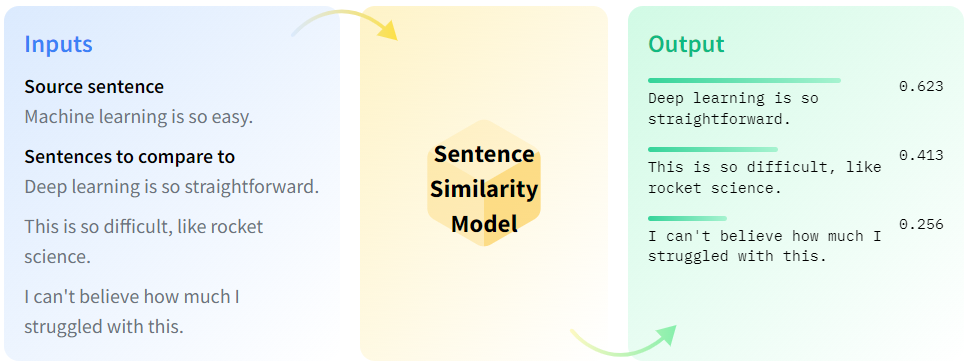
句子相似度(Sentence Similarity)是自然语言处理(NLP)中的一个关键概念,用于衡量两个句子在语义上的相似程度。换句话说,它试图判断两个句子之间的意思有多接近。句子相似度计算在许多实际应用中都有重要作用,包括但不限于以下几个领域:信息检索、文本分类、对话系统、机器翻译、抄袭检测等,常见的句子相似度计算方法有,基于向量空间模型的方法、基于上下文信息的方法、基于编辑距离的方法、基于语言模型的方法等。句子相似度计算不仅能帮助机器更好地理解人类语言,还能提升用户体验和服务智能化水平。
2024年6月,随着自然语言处理技术的不断进步,句子相似度计算在多种应用场景中愈发重要。特别推荐10款优秀的Python计算生态工具和框架,以帮助开发者了解句子相似度计算。
text2vec
text2vec, text to vector. 文本向量表征工具,把文本转化为向量矩阵,实现了Word2Vec、RankBM25、Sentence-BERT、CoSENT等文本表征、文本相似度计算模型,开箱即用。
https://github.com/shibing624/text2vec
all-MiniLM-L6-v2
这是一个句子转换器模型: 它将句子和段落映射到384维密集向量空间,可用于聚类或语义搜索等任务。
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
bge-m3
BGE-M3,全称为“多语言长文本向量检索模型”,是一款面向全球多语言场景的通用向量模型。 它旨在解决传统文本处理方法在处理多语言数据时的局限性,提供更加高效、准确的自然语言处理能力。 BGE-M3 的核心优势在于其强大的通用性。
https://huggingface.co/BAAI/bge-m3
nomic-embed-text-v1.5
nomic-embed-text-v1.5的可调整大小的生产嵌入是对利用Matryoshka表示学习的Nomic嵌入的改进,它使开发人员可以灵活地权衡嵌入大小,以使性能降低可忽略不计。
https://huggingface.co/nomic-ai/nomic-embed-text-v1.5
paraphrase-multilingual-MiniLM-L12-v2
这是一个句子转换器模型: 它将句子和段落映射到384维密集向量空间,可用于聚类或语义搜索等任务。
https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
all-mpnet-base-v2
这是一个句子转换器模型: 它将句子和段落映射到768维密集向量空间,可用于聚类或语义搜索等任务。
https://huggingface.co/sentence-transformers/all-mpnet-base-v2
gte-large-en-v1.5
我们引入了gte-v1.5系列,升级的gte嵌入,支持高达8192的上下文长度,同时进一步提高模型性能。
https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5
gte-Qwen1.5-7B-instruct
gte-Qwen1.5-7B-instruct是gte嵌入家族的最新成员。该模型从Qwen1.5-7B LLM开始设计,借鉴了Qwen1.5-7B模型强大的自然语言处理能力。
https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct
acge_text_embedding
acge text embedding是一个通用的文本编码模型,是一个可变长度的向量化模型,使用了Matryoshka Representation Learning。
https://huggingface.co/aspire/acge_text_embedding
instructor-xl
一种指令微调的文本嵌入模型,可以通过简单地提供任务指令,无需任何微调,就可以生成针对任何任务 (例如,分类,检索,聚类,文本评估等) 和领域
(例如,科学,金融等) 量身定制的文本嵌入。
Python3Turtle
