2023 Python 计算生态七月推荐榜 第65期

23年7月10日 · Python123 3699 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
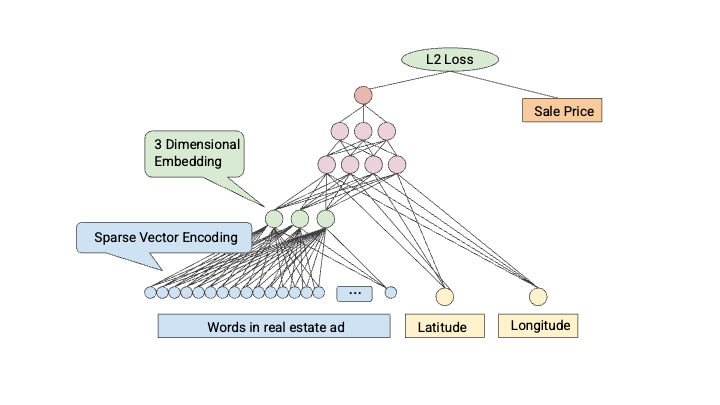
Embedding是一种将高维数据映射到低维空间的技术。在自然语言处理领域,Embedding通常指的是将单词或短语映射到一个低维向量空间中,使得相似的单词或短语在向量空间中的距离也相似,从而方便计算相似性或距离。常见的Embedding方法包括word2vec、GloVe和BERT等。在深度学习模型中,Embedding常用于输入层,将离散的单词或短语转换为连续的向量表示,以便于神经网络进行处理。例如,在文本分类任务中,可以将每个单词表示为一个向量,然后将这些向量组合成一个表示整个句子的向量,最终将该向量送入全连接层进行分类。除了自然语言处理,Embedding还可以应用于图像处理等领域。例如,在图像检索任务中,可以将每张图片表示为一个向量,然后通过计算向量之间的距离来衡量图片之间的相似度。
2023年7月,随着AI大模型的持续火热,好事者特别推荐10款优秀的Python计算生态,帮助您了解Embedding。
clip-as-service
CLIP-as-a-service是一种低延迟、高可扩展性的服务,用于嵌入图像和文本。它可以轻松地集成为神经搜索解决方案的微服务。
https://github.com/jina-ai/clip-as-service
sentence-transformers
该框架提供了一种简单的方法来计算句子、段落和图像的密集向量表示。这些模型基于像BERT / RoBERTa / XLM-RoBERTa等的转换器网络,并在各种任务中实现了最先进的性能。文本被嵌入到向量空间中,使得相似的文本彼此靠近,并可以使用余弦相似度高效地找到。
https://github.com/UKPLab/sentence-transformers
PaddleNLP
PaddleNLP是一款简单易用且功能强大的自然语言处理开发库。
https://github.com/PaddlePaddle/PaddleNLP
ImageBind
ImageBind学习跨六种不同的模态 - 图像、文本、音频、深度、热成像和IMU数据的联合嵌入。它使得新颖的应用程序可以“开箱即用”,包括跨模态检索、使用算术组合模态、跨模态检测和生成。
https://github.com/facebookresearch/ImageBind
chroma
AI本地化开源嵌入式数据库。
https://github.com/chroma-core/chroma
Top2Vec
Top2Vec是一个用于主题建模和语义搜索的算法。它可以自动检测文本中存在的主题,并生成联合嵌入的主题、文档和单词向量。
https://github.com/ddangelov/Top2Vec
pyannote/embedding
这个模型基于经典的x-vector
TDNN架构,但是将滤波器组替换为可训练的SincNet特征。有关实现细节,请参见XVectorSincNet架构。
https://huggingface.co/pyannote/embedding
flax-sentence-embeddings/all_datasets_v4_MiniLM-L6
这个模型旨在用作句子编码器。给定一个输入句子,它会输出一个向量,其中包含了句子的语义信息。该句子向量可用于信息检索、聚类或句子相似性任务。
https://huggingface.co/flax-sentence-embeddings/all_datasets_v4_MiniLM-L6
LLukas22/all-mpnet-base-v2-embedding-all
该模型是在以下数据集上对all-mpnet-base-v2进行微调得到的:squad、newsqa、LLukas22/cqadupstack、LLukas22/fiqa、LLukas22/scidocs、deepset/germanquad、LLukas22/nq。
https://huggingface.co/LLukas22/all-mpnet-base-v2-embedding-all
AnnaWegmann/Style-Embedding
这是一个基于sentence-transformers的模型:它将句子和段落映射到一个768维的稠密向量空间,可用于聚类或语义搜索等任务。
https://huggingface.co/AnnaWegmann/Style-Embedding
Python3Turtle
