2023 Python 计算生态五月推荐榜 第63期

23年5月10日 · Python123 2814 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
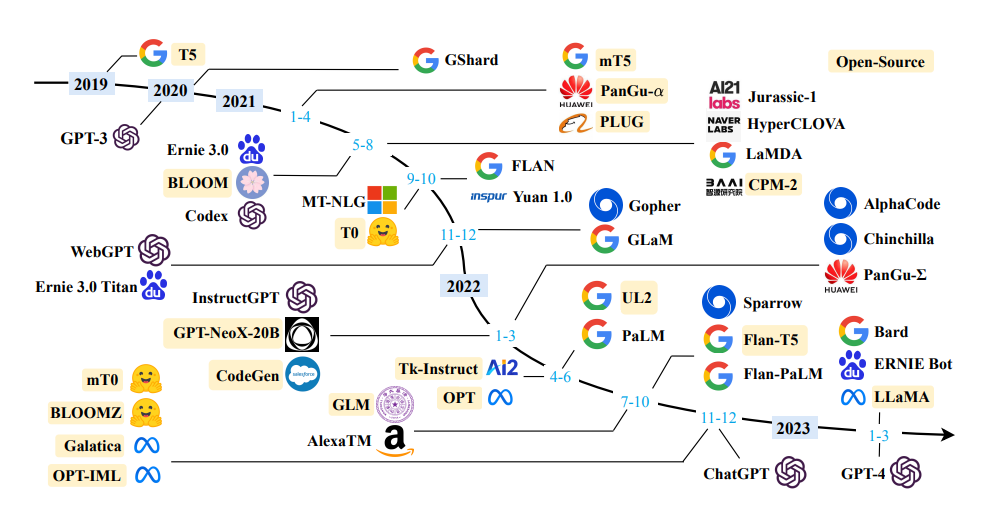
大语言模型(Large Language Model,LLM)是指能够生成大量自然语言文本的深度学习模型。它通常基于神经网络,能够通过学习大量的语言数据来自动学习语言规则和语义知识,从而生成高质量的文本内容。LLM在自然语言处理、语音识别、机器翻译、问答系统等领域中有广泛应用。其中,最著名的大语言模型是OpenAI的GPT系列模型。LLM的出现标志着自然语言处理进入了一个新的阶段,不仅能够处理简单的模式匹配和词汇替换,还可以理解更复杂的语义和上下文信息,从而更好地满足人们的语言需求。
2023年5月,随着大语言模型的不断涌现,但大部分模型都不开源,好事者特别推荐10款优秀的Python计算生态,帮助您了解大语言模型。
LLaMA
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力。
https://github.com/facebookresearch/llama
ChatGLM-6B
ChatGLM 是清华大学知识工程(KEG)实验室与其技术成果转化的公司智谱AI基于此前开源的 GLM-130B 千亿基座模型研制,是一个初具问答和对话功能的千亿中英语言模型。
https://github.com/THUDM/ChatGLM-6B
GLM-130B
GLM-130B 是清华大学与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言模型,拥有 1300亿个参数,使用通用语言模型(General
Language Model, GLM)的算法进行预训练。
https://github.com/THUDM/GLM-130B
llama_index
llama_index库是一个项目,它提供了一个中心接口,可以将您的语言模型(LLM)与外部数据连接起来。它提供了一组数据结构,可以为各种LLM任务索引大量数据,并消除了关于提示大小限制和数据摄入的问题[1]。它还支持与LangChain和LlamaHub等其他工具或库的集成。
https://github.com/jerryjliu/llama_index
Chinese-LLaMA-Alpaca
中文LLaMA模型和指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
https://github.com/ymcui/Chinese-LLaMA-Alpaca
lit-llama
由pytorch-lightening发起的项目,目前还处于概念阶段。这个项目的想法是把LLaMA的设计用自己的代码重写一边,这样绕过它的代码证书,再训练出一个完全开源版本的LLaMA。
https://github.com/Lightning-AI/lit-llama
LLaMA-Adapter
LLaMA-Adapter,一种轻量级的适应方法,可以有效地将 LLaMA 微调为一个跟随指令的模型。LLaMA-Adapter 使用 52K 个自我指示的样例,在冻结的
LLaMA 7B 模型上只引入了 120 万个可学习参数,在 8 个A100 GPU 上进行微调的成本不到 1 小时。
https://github.com/ZrrSkywalker/LLaMA-Adapter
pyllama
pyllama是基于原始 Facebook 实现的“泄露”版本LLaMA,更方便在单个消费级 GPU 中运行。
https://github.com/juncongmoo/pyllama
text-generation-webui
一个用于运行 GPT-J 6B、OPT、GALACTICA、LLaMA 和 Pygmalion 等大语言模型的 gradio web UI。
https://github.com/oobabooga/text-generation-webui
llama-hub
这是社区创建的所有数据加载器/读取器的简单库。目标是使将大型语言模型连接到各种知识源变得极其容易。
https://github.com/emptycrown/llama-hub
Python3Turtle
