2021 Python 计算生态九月推荐榜

21年9月10日 · Python123 4970 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
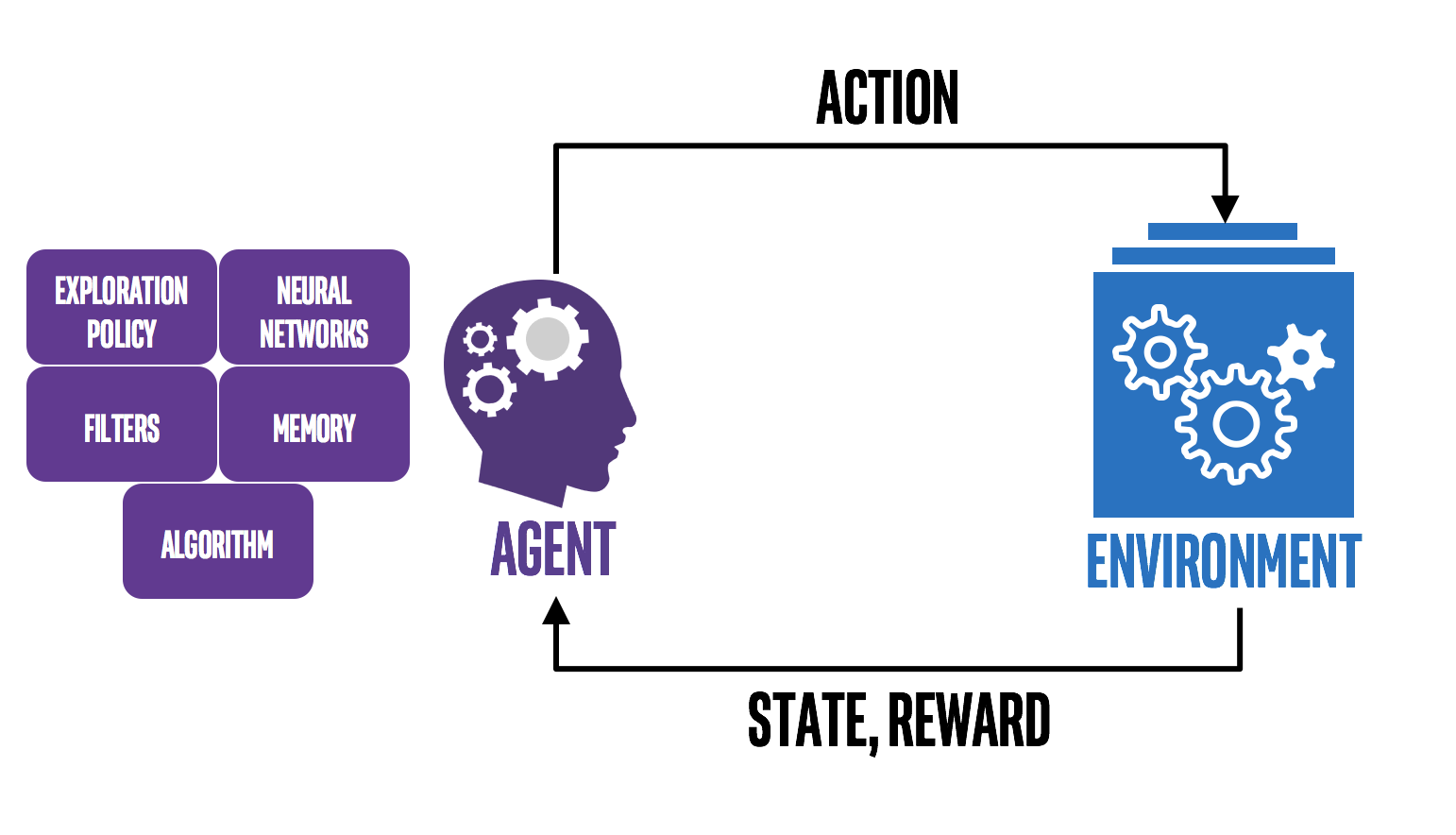
强化学习(Reinforcement learning,简称:RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益,强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。在强化学习中,人工智能面临着类似游戏的情况,计算机通过反复试验来提出问题的解决方案,为了让机器按照程序员的意愿行事,人工智能会因其执行的操作而获得奖励或惩罚,它的目标是最大化奖励。设计者设定了奖励政策,即游戏规则,但他不会给模型任何提示或建议,模型需要弄清楚如何执行任务以最大化奖励,从完全随机的试验开始,并以复杂的策略和超人的技能结束。
2021年9月,强化学习(RL)的快速发展导致对易于理解和使用方便的RL工具的需求不断增长。好事者特别推荐10款优秀的Python计算生态,为您的项目选择合适的强化学习库。
Gym
OpenAPI Gym是一款用于研发和比较强化学习算法的工具包,它支持训练智能体(agent)做任何事——从行走到玩Pong或围棋之类的游戏都在范围中。
 |
RLlib
RLlib
是一个用于强化学习的开源库,为各种应用程序提供高可扩展性和统一的 API。RLlib 本身支持 TensorFlow、TensorFlow Eager 和 PyTorch,但其大部分内部结构与框架无关。
 |
https://github.com/ray-project/ray
dopamine
dopamine是一个用于强化学习算法快速原型设计的研究框架。它旨在满足对一个小型、易于理解的代码库的需求,用户可以在其中自由地尝试疯狂的想法(推测性研究)。
 |
https://github.com/google/dopamine
KerasRL
KerasRL是一个深度强化学习Python 库。它实现了一些最先进的 RL 算法,并与深度学习库Keras无缝集成。此外,KerasRL 开箱即用地与OpenAI Gym配合使用。这意味着您可以很容易地评估和使用不同的算法。
https://github.com/keras-rl/keras-rl
stable-baselines
Stable
Baselines是一组基于OpenAI Baselines的强化学习(RL) 算法的改进实现。
 |
https://github.com/hill-a/stable-baselines
tensorforce
Tensorforce是一个基于谷歌Tensorflow框架的开源强化学习库,它的用法很简单,有可能成为最好的强化学习库之一。
https://github.com/tensorforce/tensorforce
acme
Acme 是一款用于构建可读、高效、研究型强化学习算法的框架,核心理念在于实现对强化学习智能体的简单描述,使得智能体在各种规模下运行,包括分布式智能体。研究者在设计 Acme 的过程中也充分考虑到了不同规模智能体之间的差异,并弥合了大中小型实验之间的差别。
 |
https://github.com/deepmind/acme
rl_coach
Coach
是一个 Python 强化学习框架,包含许多最先进算法的实现。它公开了一组易于使用的 API,用于试验新的 RL 算法,并允许新环境的简单集成来解决。基本的 RL 组件(算法、环境、神经网络架构、探索策略等)很好地解耦,因此扩展和重用现有组件是相当轻松的。
 |
https://github.com/IntelLabs/coach
TFAgents
TFAgents是一个 Python 库,旨在简化RL 算法的实现、部署和测试。它具有模块化结构,并提供经过良好测试的组件,可以轻松修改和扩展。
https://github.com/tensorflow/agents
garage
garage 是一个用于开发和评估强化学习算法的工具包,以及一个使用该工具包构建的附带库。
Python3Turtle
