Day 93:第一步和下一步

18年11月20日 · 史二美—北京理工大学 6477 人阅读
第一步和下一步
如果大家计划为上下文无关的语法实现自己的解析器,那么第一组和后续集的构造将是您必须花费时间的第一个算法。由于正式语言和语法的定义比我们目前所需要的要复杂得多,所以我们将会进行直观的解释。
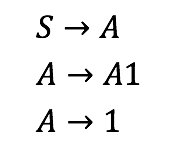 |
上下文无关文法是一组由终端和非终端组成的生成规则.终端是可能出现在解析文本中的“物理”字符。非终端是一个“元”字符,必须发生在生产规则的左边。
在上面的语法中,S,A是非终末,而1是终端.
 |
我们从一个起始符号S开始,并使用生产规则重复重写非终端.一旦序列只包含终端,我们就会得到语法所接受的单词。
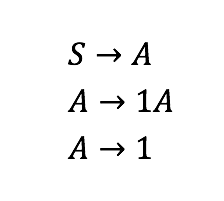 |
注意,这个语法与第一个语法不同,但它产生的语言是相同的。
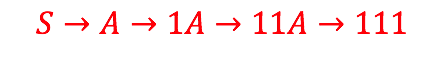 |
由于每个语法中的第二个规则,第一个规则称为左递归规则,第二个规则称为右递归规则。
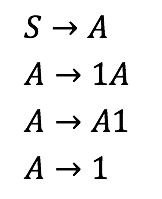 |
第三种语法也描述了同一种语言。这两者都是,左递归和右递归[这不是一件好事]。更糟糕的是,它是模棱两可的,因为它可以通过不同的产品产生同一个单词。
 |
歧义是非常糟糕的,并且有不同类型的解析器以不同的方式处理这类问题。
 |
最后一种语法能够生成带有匹配括号的任何有限单词。如果您知道正则表达式,您可能知道不可能编写与任意数量的括号匹配的正则表达式。这就是使上下文无关语法对编译器如此重要的原因-它是最简单的语法,足以描述编程语言的语法。
现在,回到算法。
第一组列举非终端开始时可能使用的终端。下面的集合列举了可能的终端,这些终端可以是非终端的。查看我在本文末尾提供的两个示例。当您构建解析器时,无论是SLR、LALR、LR(K)还是LL(K),您都需要构造第一个和后续的集合。这些集合用于构建一个解析表,以控制处理语言的有限状态自动机。
算法实现
左递归法
测试一
测试二
测试三
算数表达式
测试一
测试二
测试三
Python3Turtle
