Day 92:主成分分析问题(PCA)

18年11月20日 · 史二美—北京理工大学 2291 人阅读
PCA(Principal Component Analysis))在我们需要使用可视化高维数据时非常有用,它的实现也非常简单,但需要事先做大量的工作,我们希望使用PCA来满足这样的需求。
假设我们有一堆多维数据存储在一个矩阵X中。每一行代表一个样本,每个列代表一个变量。
我们认为,如果两个变量之间存在线性关系,它们是相关的。他们的散射点看起来可能和这个相似。
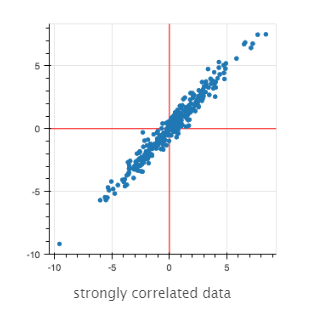 |
另一方面,下一个散射点上的变量是不相关的。
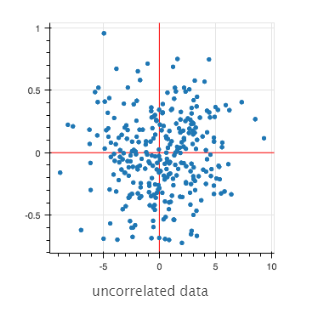 |
虽然第一个情节似乎更有用,PCA却利用了第二个情节的优势。
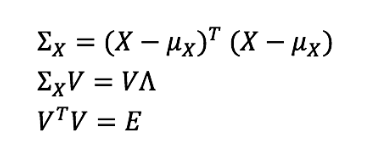 |
为了研究这些变量之间的依赖关系,我们使用了一个协方差矩阵。当数据没有相关变量时,Σ矩阵的所有非对角线元素必须为零。另外,对于任何协方差矩阵Σ,都存在着矩阵V称为特征向量矩阵,对角矩阵Λ称为特征值矩阵,从而使上述表达式成立。除了列的顺序外,这两个矩阵都是唯一的。
那么PCA是如何工作的呢?
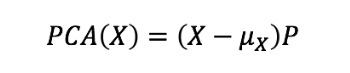 |
主成分分析将数据矩阵X归一化为零均值,然后由某个矩阵P进行倍数。乘法实际上是数据的线性变换。这意味着如果我们非常小心地选择P,我们可以旋转、缩放或将数据投影到向量子空间。
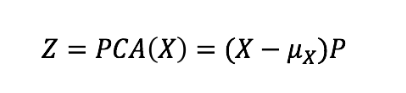 |
假设我们已经将主成分分析应用于数据矩阵X,并得到了另一个矩阵Z。关于Z的Σ矩阵,我们知道些什么?
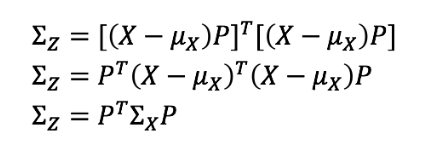 |
X和Z的协方差矩阵之间存在[二次]关系!如果我们选择P作为上面定义的特征向量矩阵V,会发生什么呢?
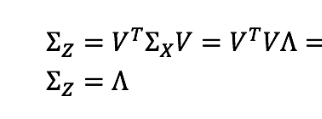 |
这意味着投影矩阵Z是不相关的,它的变量不再有任何类型的线性依赖(因为Λ是对角矩阵)。
等等!刚刚发生了什么?
让我给你们展示一个例子和另一个观点。
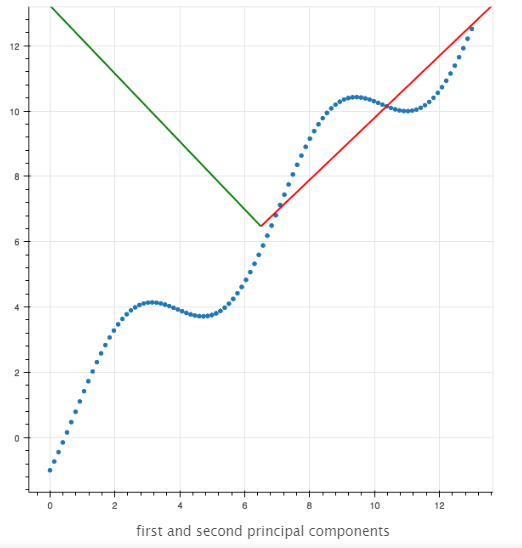 |
主成分分析发现数据的均值和主成分。对于二维数据,主成分是轴x和y旋转到数据变得不相关的点。还有另一个经常使用的术语。我们说第一个主成分是x轴的旋转,以使投影到它上的数据的方差最大化。
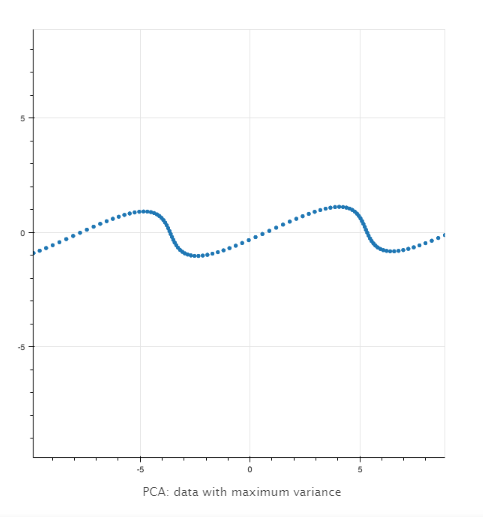 |
PCA只是坐标系的旋转吗?这究竟有什么用呢?
如果你看下面的代码,我们将会生成一组二进制向量,每个向量有30个维度。
 |
|
数据中有线性关系吗?答案是肯定的:有,因为我们生成的数据有一个[虽然它可能不是立即明显的]。但在实践中,我们不知道,也想找出答案。预先,我生成的每一个向量都位于30D单位立方体的角落,人类大脑无法对这类信息进行排序。当我们将PCA应用于这些数据时,所有的变量都变得不相关,并且维数现在尽可能多地相互独立地保存信息,并且按降序排列。此外,从30D到2D的投影现在很简单-只需删除28个尾随变量(因为变量是独立的)并绘制图表。
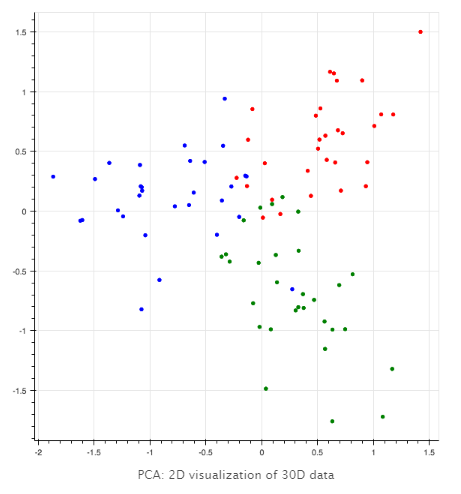 |
如您所见,从30D投影到2D的数据仍然包含我生成的相同颜色的向量以彼此接近的关键信息。每组30个向量形成一个很好的簇(但是我需要说背后的原因是因为我仔细地生成了数据来形成这样的集群)。我希望有更多的时间。最后一个样本,30D单位立方体的角点,使我们转向最有趣的话题,潜在因素分析,这也提供了另一个观点的PCA和更先进的技术。
不管怎样,如何实现PCA呢?
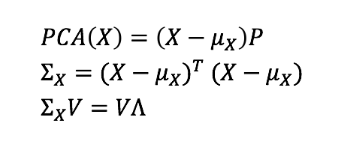 |
1:正规化X到零均值
2:计算协方差矩阵Σ
3:求出Σ的[正交]特征向量
代码实现
二维数据&主成分
二元向量降维
Python3Turtle
